How to download YouTube data in R using “tuber” and “purrr”
Accessing YouTube’s metadata such as views, likes, dislikes and comments is simple in R thanks to thetuber package by Gaurav Sood. Sood wrote an excellent, easy-to-use package for accessing the YouTube data API. If you’re like me, you love screenshots for setting up new tools like these. Below is a quick outline for the steps to get your application id and password set up in R.
First. make sure you install the packages and load it with library().
install.packages("tuber")
library(tuber) # youtube API
library(magrittr) # Pipes %>%, %T>% and equals(), extract().
library(tidyverse) # all tidyverse packages
library(purrr) # package for iterating/extracting data1) Enable the APIs
First head over to your Google APIs dashboard (you’ll need an account for this). Click on “ENABLE APIS AND SERVICES”.
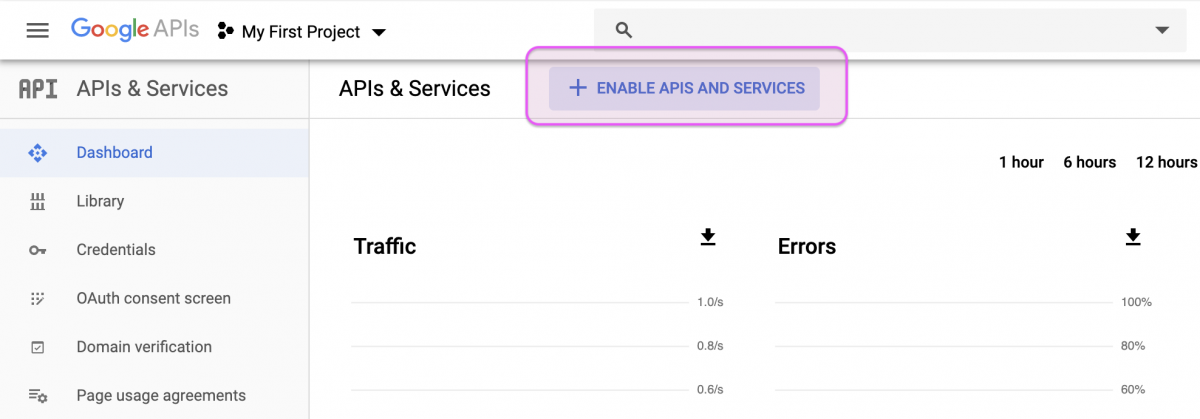
This will bring up a laundry list of APIs, but we only need the four pertaining to YouTube (see below) and the Freebase API.
Click on the search bar and type in YouTube and you should see four options. Enable all of them.
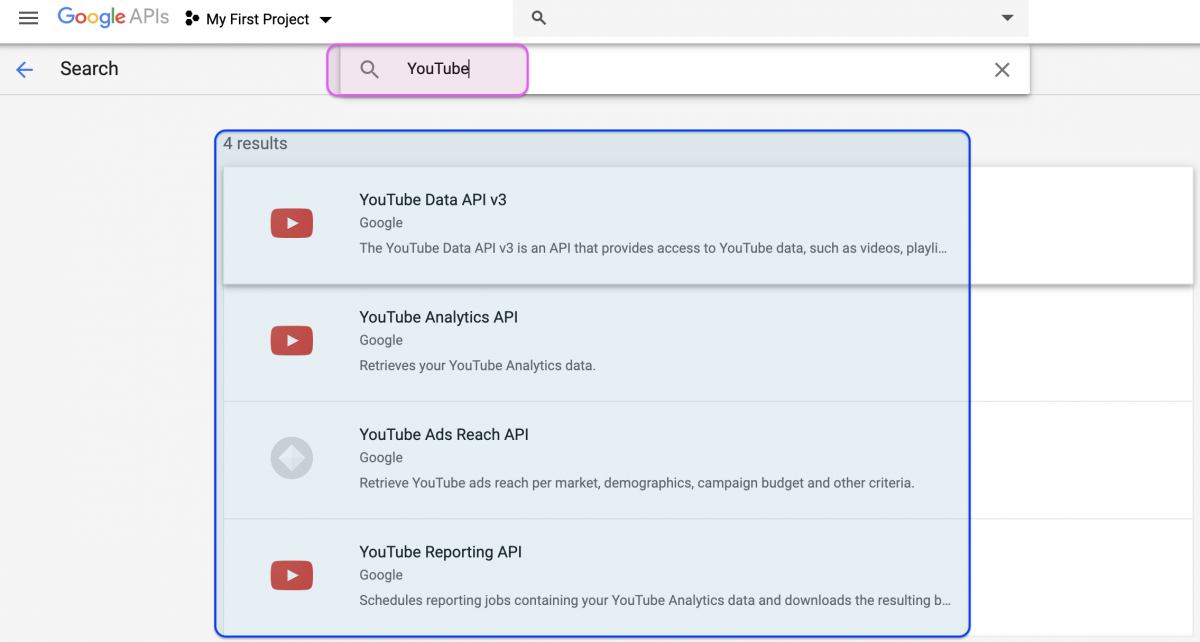
IMPORTANT you’ll also have to search for and enable the Freebase API.
2) Create your credentials
After these have been enabled, you’ll need to create credentials for the API. Click on the Credentials label on the left side of your Google dashboard (there should be a little key icon next to it).
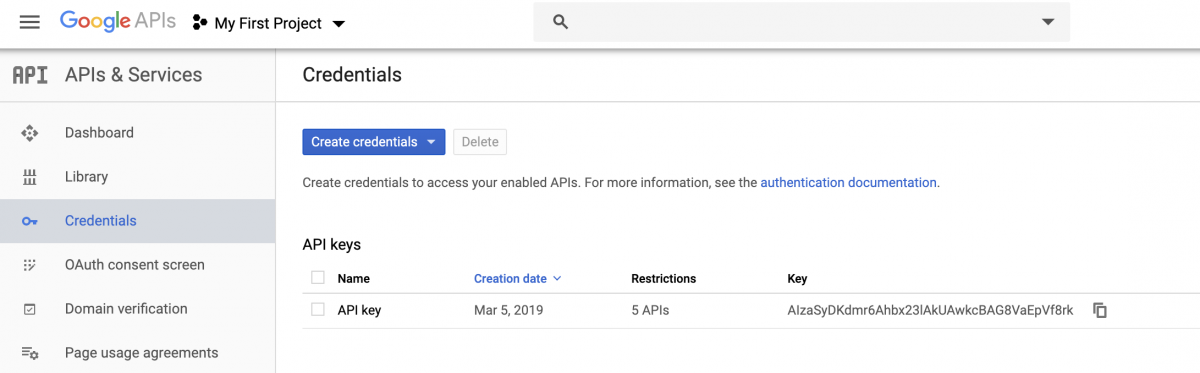
After clicking on the Credentials icon, you’ll need to select the OAuth client ID option.
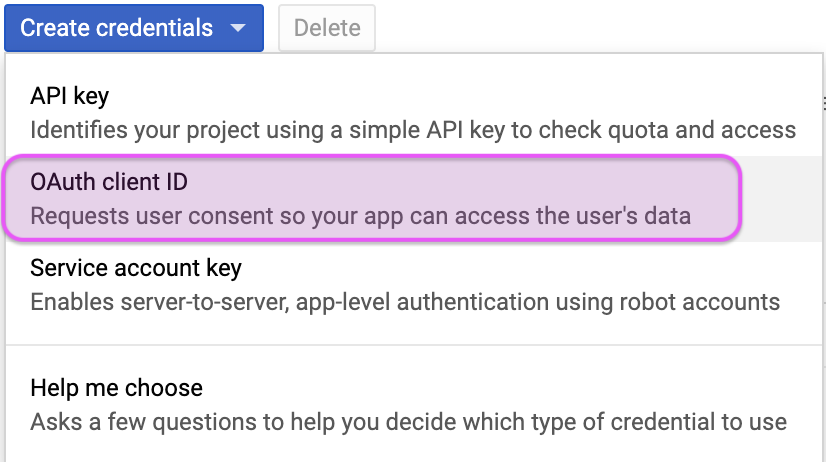
Create your OAuth
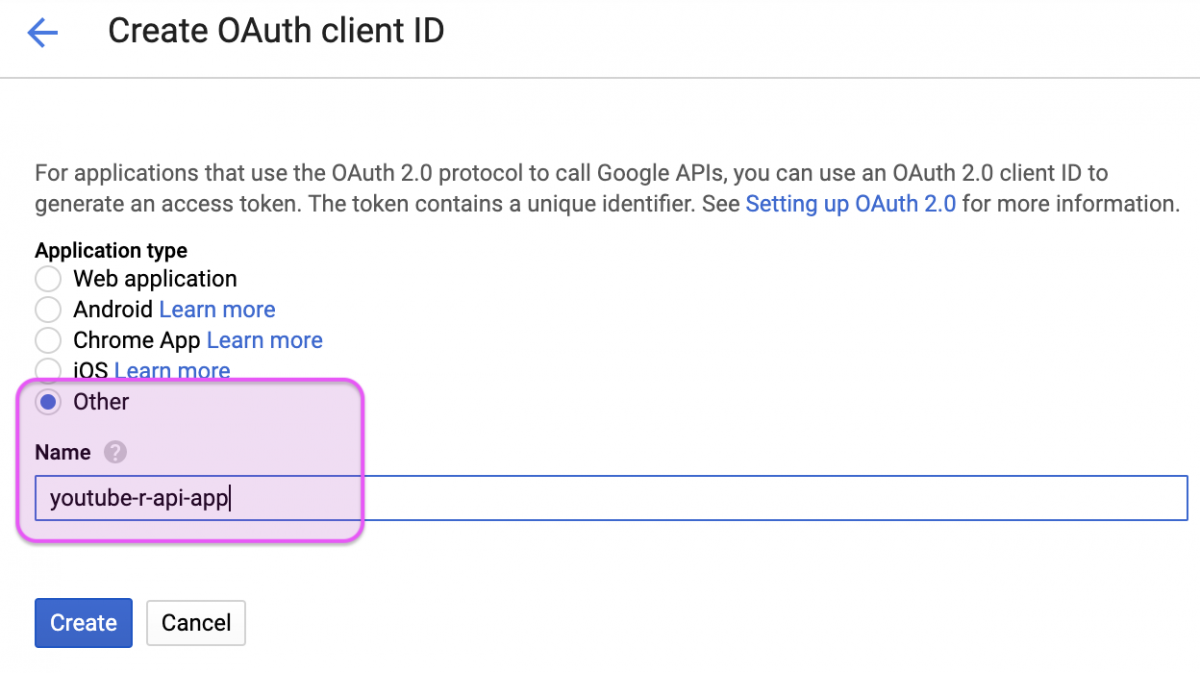
Here is where we name our app and indicate it’s an “Other” Application type.
We’re told we’re limited to 100 sensitive scope logins until the OAuth consent screen is published. That’s not a problem for us, so we can copy the client ID and client secret
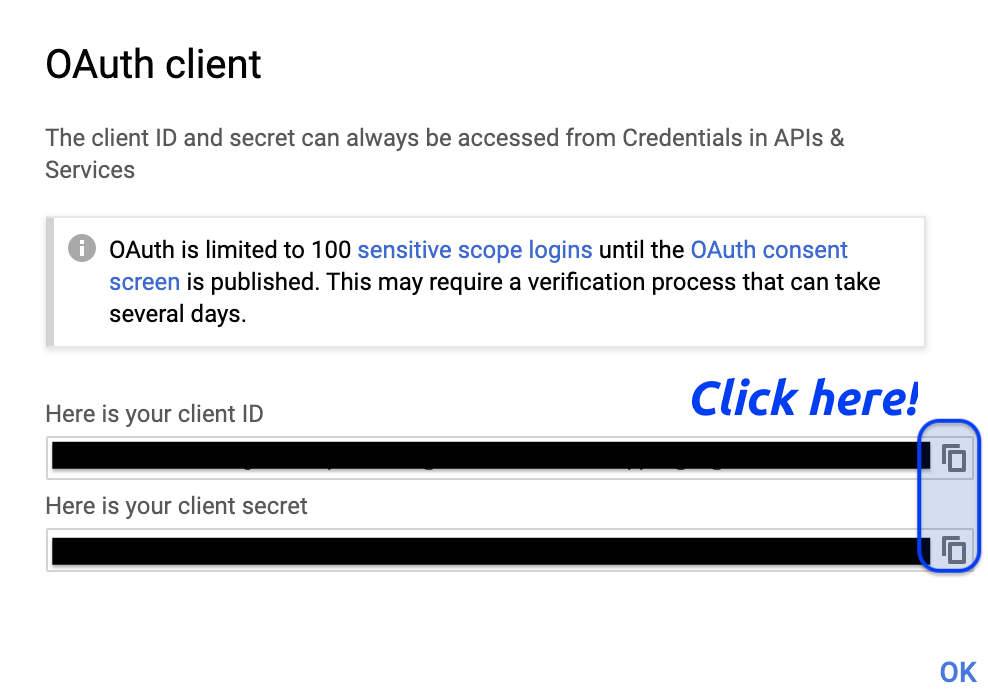
After clicking on the copy icons, we save them into two objects in RStudio (client_id and client_secret).
client_id <- "XXXXXXXXX"
client_secret <- "XXXXXXXXX"3) Authenticate the application
Now you can run tuber’s yt_oauth() function to authenticate your application. I included the token as a blank string (token = '') because it kept looking for the .httr-oauth in my local directory (and I didn’t create one).
# use the youtube oauth
yt_oauth(app_id = client_id,
app_secret = client_secret,
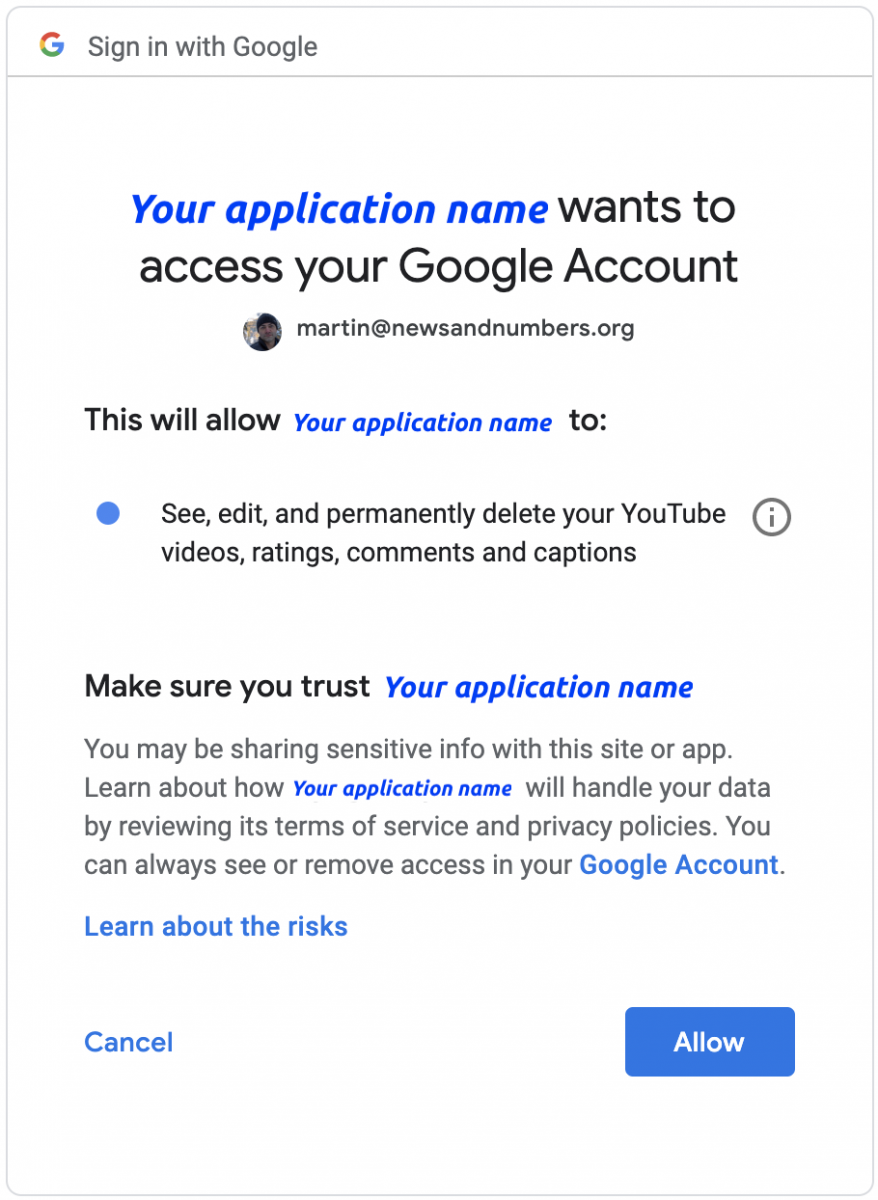
token = '')Provided you did everything correct, this should open your browser and ask you to sign into the Google account you set everything up with (see the images below). You’ll see the name of your application in place of “Your application name”.
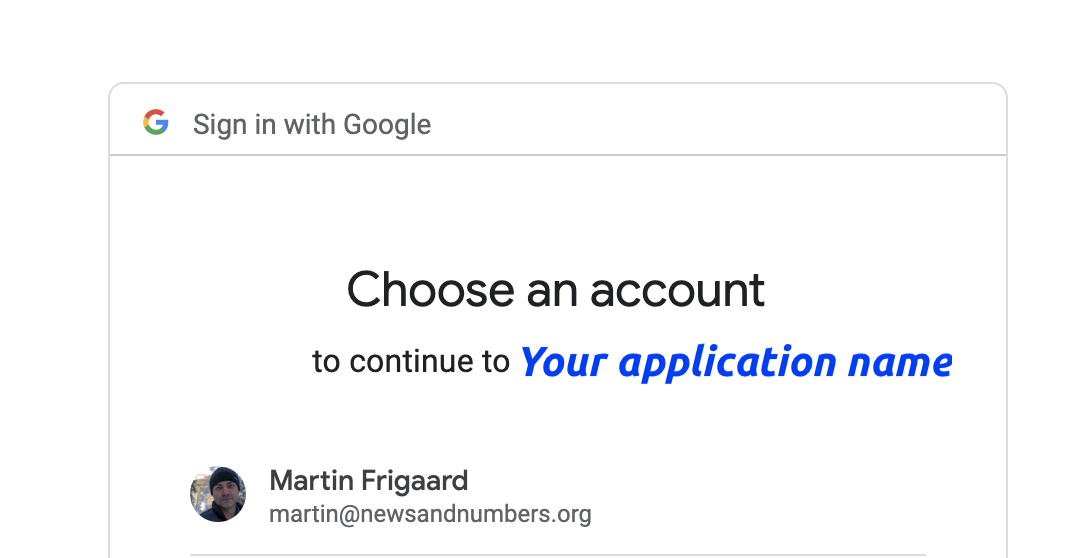
After signing in, you’ll be asked if the YouTube application you created can access your Google account. If you approve, click “Allow.”
This should give you a blank page with a cryptic, Authentication
complete. Please close this page and return to R. message.
Accessing YouTube data
Great! Now that we’re all set up, we will download some data into RStudio. Be sure to check out the reference page and the YouTube API reference doc on how to access various meta data from YouTube videos.
We’ll download some example data from Dave Chappelle’s comedy central playlist, which is a collection of 200 of his most popular skits.
Downloading the playlist data
We will be using the playlistId from the url to access the content from the videos. Here is some information on the playlistId parameter:
The
playlistIdparameter specifies the unique ID of the playlist for
which you want to retrieve playlist items. Note that even though this
is an optional parameter, every request to retrieve playlist items
must specify a value for either theidparameter or theplaylistId
parameter.
Dave Chappelle’s playlist is in the url below. We pass it to the
stringr::str_split() function to get the playlistId out of it.
dave_chappelle_playlist_id <- stringr::str_split(
string = "https://www.youtube.com/playlist?list=PLG6HoeSC3raE-EB8r_vVDOs-59kg3Spvd",
pattern = "=",
n = 2,
simplify = TRUE)[ , 2]
dave_chappelle_playlist_id
[1] "PLG6HoeSC3raE-EB8r_vVDOs-59kg3Spvd"Ok–we have a vector for Dave Chappelle’s playlistId named dave_chappelle_playlist_id, now we can use the tuber::get_playlist_items() to collect the videos into a data.frame.
DaveChappelleRaw <- tuber::get_playlist_items(filter =
c(playlist_id = "PLG6HoeSC3raE-EB8r_vVDOs-59kg3Spvd"),
part = "contentDetails",
# set this to the number of videos
max_results = 200) We should check these data to see if there is one row per video from the playlist (recall that Dave Chappelle had 200 videos).
# check the data for Dave Chappelle
DaveChappelleRaw %>% dplyr::glimpse(78)
Observations: 200
Variables: 6
$ .id "items1", "items2", "items3", "item…
$ kind youtube#playlistItem, youtube#playl…
$ etag "p4VTdlkQv3HQeTEaXgvLePAydmU/G-gTM9…
$ id UExHNkhvZVNDM3JhRS1FQjhyX3ZWRE9zLTU…
$ contentDetails.videoId oO3wTulizvg, ZX5MHNvjw7o, MvZ-clcMC…
$ contentDetails.videoPublishedAt 2019-04-28T16:00:07.000Z, 2017-12-3…
Collecting statistics from a YouTube playlist
Now that we have all of the video ids (not .id), we can create a function that extracts the statistics for each video on the playlist. We’ll start by putting the video ids in a vector and call it dave_chap_ids.
dave_chap_ids <- base::as.vector(DaveChappelleRaw$contentDetails.videoId) dplyr::glimpse(dave_chap_ids) chr [1:200] "oO3wTulizvg" "ZX5MHNvjw7o" "MvZ-clcMCec" "4trBQseIkkc" ...
tuber has a get_stats() function we will use with the vector we just created for the show ids.
# Function to scrape stats for all vids
get_all_stats <- function(id) {
tuber::get_stats(video_id = id)
} Using purrr to iterate and extract metadata
Now we introduce a bit of iteration from the purrr package. The purrr package provides tools for ‘functional programming,’ but that is a much bigger topic for a later post.
For now, just know that the purrr::map_df() function takes an object as .x, and whatever function is listed in .f gets applied over the .x object. Check out the code below:
# Get stats and convert results to data frame
DaveChappelleAllStatsRaw <- purrr::map_df(.x = dave_chap_ids,
.f = get_all_stats)
DaveChappelleAllStatsRaw %>% dplyr::glimpse(78)
Observations: 200
Variables: 6
$ id "oO3wTulizvg", "ZX5MHNvjw7o", "MvZ-clcMCec", "4trBQse…
$ viewCount "4446789", "19266680", "6233018", "8867404", "7860341…
$ likeCount "48699", "150691", "65272", "92259", "56584", "144625…
$ dislikeCount "1396", "6878", "1530", "2189", "1405", "3172", "1779…
$ favoriteCount "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0"…
$ commentCount "2098", "8345", "5130", "5337", "2878", "9071", "4613…
Fantastic! We have the DaveChappelleRaw and DaveChappelleAllStatsRaw in two data.frames we can export (and timestamp!)
# export DaveChappelleRaw
readr::write_csv(x = as.data.frame(DaveChappelleRaw),
path = paste0("data/",
base::noquote(lubridate::today()),
"-DaveChappelleRaw.csv"))
# export DaveChappelleRaw
readr::write_csv(x = as.data.frame(DaveChappelleAllStatsRaw),
path = paste0("data/",
base::noquote(lubridate::today()),
"-DaveChappelleAllStatsRaw.csv"))
# verify
fs::dir_ls("data", regexp = "Dave")
Be sure to go through the following purrr tutorials if you want to learn more about functional programming:
- R for Data Science by H. Wickham & G. Grolemund
- purrr Tutorial by J. Bryan
- A purrr tutorial - useR! 2017 by C. Wickham
- Happy dev with {purrr} - by C. Fay
Also check out the previous post on using APIs.
- Getting started with stringr for textual analysis in R - February 8, 2024
- How to calculate a rolling average in R - June 22, 2020
- Update: How to geocode a CSV of addresses in R - June 13, 2020



how to relosve this error
> DaveChappelleRaw <- tuber::get_playlist_items(filter =
+ c(playlist_id = "PLG6HoeSC3raE-EB8r_vVDOs-59kg3Spvd"),
+ part = "contentDetails",
+ # set this to the number of videos
+ max_results = 200)
Error: HTTP failure: 403
Without seeing your console, I think it might be due to either your Oauth setup. If you’re encountering problems with a different video, you might want to check out the following thread: https://github.com/soodoku/tuber/issues/15
I can’t seem to be able to authenticate because the app is not verified and I need to submit a verification request. Did you have this trouble?
Thank you a lot for this tutorial! Despite being a dum dum I managed to go through Google authentication and gather all needed ID’s and secrets to launch this ‘tuber’ package 🙂 I would gave up three more times if I wouldn’t find your website! 🙂
The application type doesn’t have an option of ‘other’. What should I do?
+1