
Whose Quotes Get Cleaned Up? How News Orgs Normalize Some Voices and Scrutinize Others
In mid-February, The New York Times ignited a storm of criticism with a piece about Representative Alexandria Ocasio-Cortez at a security conference in Munich.The article was critical (the headline included the phrase “with some stumbles”) but the anger it provoked was caused by a verbatim quote that included repeated “ah”s, “um”s, and “uh”s. We all speak like that while thinking out loud, but even the Times’ own Guidelines on Integrity indicate that “The writer should, of course, omit extraneous syllables like ‘um’ and may judiciously delete false starts.” Was this sloppiness? A hit piece on AOC? Or was this a signal of something deeper about how mainstream news edits quotes? I dove in with some code, genAI, and theories to try and find out more about this kind of “quote cleaning.” What I found suggests that including “um” is incrediblyrare and opens up deeper questions about how quotes operate in news to normalize some speakers and scrutinize others.

The Politics of Quotes in News
It’s typical, and even helpful, for journalists to tidy up a direct quote for better readability. We teach this in journalism schools and many media outlets codify this in editing policies (as those Times guidelines demonstrate). That said, the practice is largely invisible: I doubt most readers think about whether the words in quotes exactly match every sound the speaker uttered. This kind of quote cleaning is an editorial choice, and like all others, it embeds values. In this case those values are likely to reflect underlying ideas about what counts as articulate, authoritative speech. Who sounds smart? Who sounds right?
This isn’t a surprising comment in the context of our racialized politics. Black Speech and Spanglish are often used by political leaders in those communities, yet seem to show up less often in news quotes. Any multi-cultural person knows the norms of code switching in language to match the dominant audience expectations. A high-profile recent example is Kamala Harris, who was criticized as being inauthentic because she spoke using different vernaculars to differing audiences.
Consider a more contemporary counter-example: President Trump. His often-incoherent rambling statements have challenged editorial quoting norms (among so many others norms he’s challenged). A whole new term — “sane-washing” — has come into vogue as part of related media critiques. Responses have ranged from the NPR Public Editor’s explanatory engagement, to op-eds decrying the coverage, to criticism of how little what Trump actually says is quoted.
These anecdotes suggest a pattern where high-status white politicians often get their quotes cleaned up as a matter of course, but others who don’t belong to that dominant group might not receive the same treatment. AOC sits at the latter group, as a Latina progressive women. This editing from the Times lands differently with that in mind.
Can Data Help Us Understand This?
To investigate this specific example, I decided to see how often “um” and “ah” were included in quotes in the most visited US online news site on the same day that article was published (Feb 13, 2026). Conveniently, when we want to answer questions like these we have a wealth of technologies at hand to help. Specifically, with my colleagues Meg Heckman and Elisabeth Hadjis, I just published a paper in News Research Journal about using genAI prompts to extract quotes from news stories (something traditional machine learning doesn’t do well). I remixed methods from that older work to answer this question about just how rare including those utterances was that day.My analysis included 36,045 quotes across 8,066 articles published by those 45 news sources on Feb 13th. From those quotes, just eight quotes included “um”; one was from AOC while the rest were non-politicians. That’s just 0.02%! Even less, just three stories, included “ah”; none from politicians. I can confidently conclude that including “um” or “ah” in a quote from a high-profile politician on Feb 13th was a very statistically rare choice.
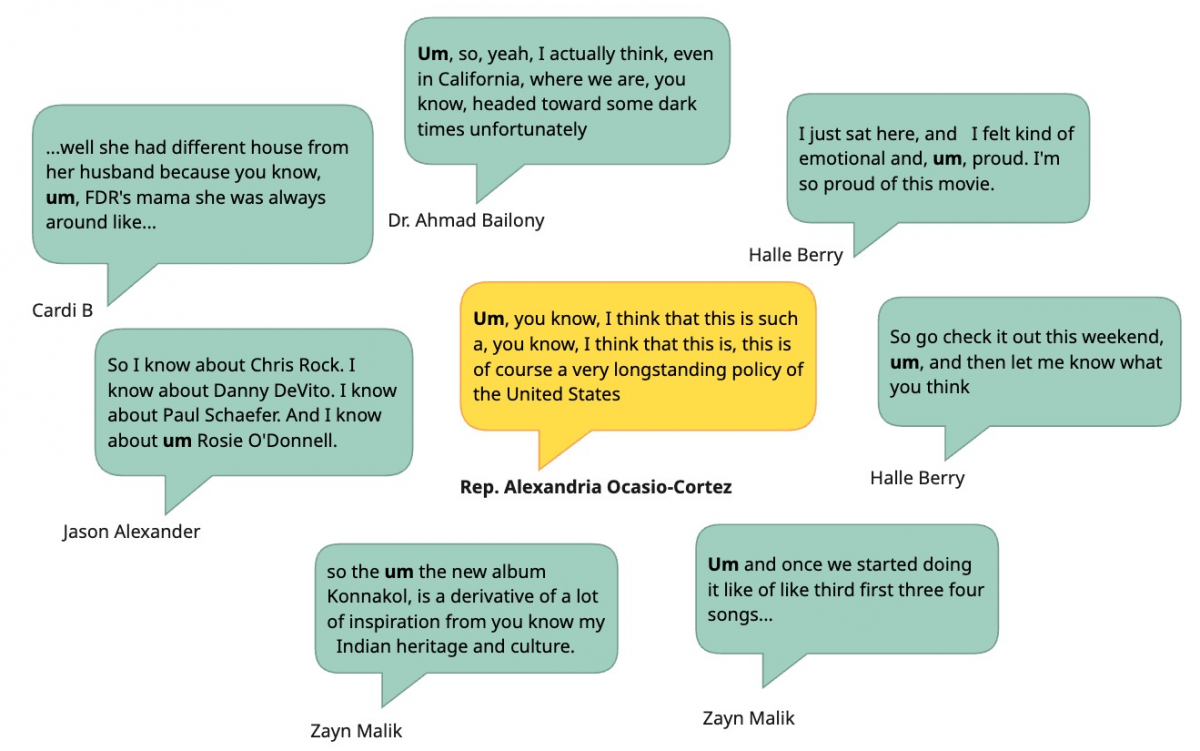
Of course, since I don’t have raw transcripts for all those stories I can’t tell you how many dialectical markers, code-switches, and instances of non-standard grammar were removed. I’d be curious to investigate this more for politicians who carry multiple identities, to see if there are keywords from a dialect indicative of code switching that I could track across how they’re quoted in news stories. Consider this an invitation to explore more: my little experiment suggests that we have the tools to answer these kinds of questions.
How’d I do this?
Curious to try this kind of thing yourself? Here’s a bit more about how I found these results. I remixed our prior approach from that paper with a set of the most-visited online US news sources, the Media Cloud online news archive, a revised prompt for genAI, evaluation with the DSPy library, and a small set of duct-tape scripts to see what the data said about how normal, or not, that quote was. I’m a hesitant generative AI user, so at each step where I used it I tried to be thoughtful about how to check the validity of the results it gave me. I call this my “genAI-last” approach; I try to use any other reasonable computational methods before falling back to genAI to help me solve some research analysis problem.
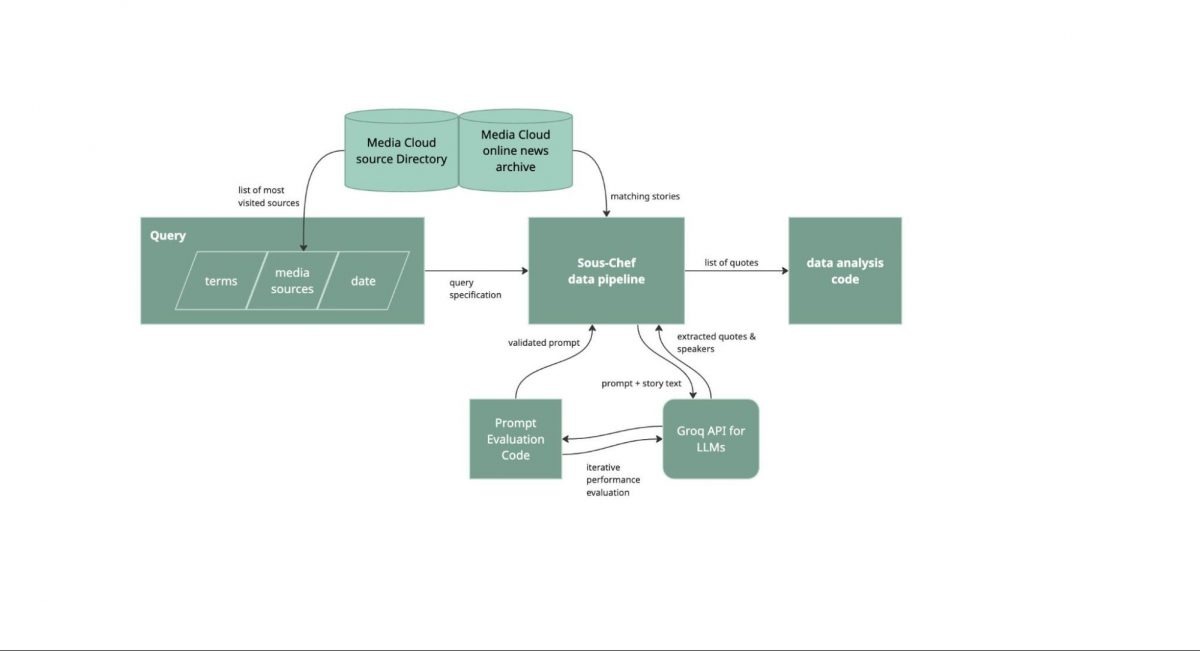
I began by defining what media sources I cared about. The seed here was the Times, so I thought it made sense to focus on some reasonable set of large mainstream online news outlets. Media Cloud has a collection of “Most Visited” news websites from January 2026, based on SimilarWeb data as published monthly by the PressGazette. I can’t really speak to the full methods they use to collect their numbers, but SimilarWeb data is widely used and the list looked reasonable to me. This particular list from Media Cloud was already filtered for other work for US-based publications, which worked well because I wanted to look at American editorial norms.
With that list of publications in hand, I used the Media Cloud web-based search tools and API to pull all stories from those websites on Feb 13, because I just wanted a one-day snapshot for this short blog post. Then I remove duplicate stories based on if there was a story with the same title from the same outlet on that day, because often the same story is published at multiple URLs. That left me with 8,066 unique stories.
In parallel, I iterated on creating a genAI prompt and evaluation set that’d help me extract quotes from stories and attribute them to speakers. An earlier version of that News Research Journal work we presented at the 2024 Computation + Journalism Symposium gets more into details about why, but there isn’t really an off-the-shelf open solution for extracting and attributing quotes. In general for this kind of work with AI models it is important to (1) define your task, (2) build a ground-truth evaluation dataset, and (3) create an evaluation and scoring rubric. To start the genAI eval I pulled a handful of stories and identified quotes and speakers by hand; this would be my evaluation dataset to see how well different prompts and models worked. To test things I used DSPy, is a great Python library for iterating on and evaluating genAI prompts. An existing account on the cloud-based Groq model provider let me run test prompts against this evaluation set with various genAI models. I iterated with Claude, ChatGPT, and Geimini on refining the prompt for specific genAI models, and ended up seeing best performance on a prompt that Claude expanded for the llama-3.3-70b-versatile open source mode (recall and precision both over 0.95). If this was a more developed project, I would have evaluated against more hand-labelled ground truth data and evaluated multiple runs of the same data (because genAI models aren’t consistent, by design).
With a prompt and dataset in hand, I then just needed to run the prompt against each story. Here at Media Cloud we have an internal-for-now data pipeline tool called “Sous Chef” for this, so without too much effort I was able to get the results back as a CSV of quotes with related story metadata. I used some simple code in a Python notebook to exact and identify quotes with “um” or “ah” in them, using Spacy to tokenize the terms (see the code and data). For each of these stories I went back to read it to make sure the quote and speaker identified by the AI model were correct.
This process took me about a day of work, split across a week of divided attention. This array of tools really has put this kind of quick media investigation within reach and presents very exciting opportunities to learn about norms in the news.
So what?
Why does it matter if editors and journalists “clean up” speech like this? I spoke with long-time Boston Globe editor Mary Creane to get her take. Creane started by noting that in news it’s “not our job is not to make people look stupid; on the other hand our job is to present people as they are.” As a rule, she said she would “never change their quote.” Instead, if the choice was made to remove an “um“ or “ah”, she would use ellipses to make clear that some words in the quote had been taken out.
Creane emphasized the difference between speaking well and making a good point. Former vice-presidential candidate and Alaska governor Sarah Palin, for instance, claimed to be a foreign policy expert because you can see Russia from Alaska, which Creane noted was “not ungrammatical, but points out a weakness.” In situations where the speaker you want to quote is speaking poorly, but making a relevant point, an alternative is to paraphrase. In a very classic sense Creane believes that as journalists “our job is to say ‘here’s all the information, make of it what you will.’” When it comes to editing quotes appropriately, the core question for her is “if we’re not fair, if we don’t have integrity, then who are we?”
For me, this integrity was lacking in how the Times quoted Ocasio-Cortez. The quote used was aligned with the critical tone of the article, but intentionally broke policy and norms to portray her as ill-equipped due to the form of her comment, not the substance.
Despite all the change driven by social media, online news is still a strong driver of public understanding and shapes perceptions of those in power. This example says something about what types of voices we amplify and showcase in society, and where and when everyone is allowed to speak as their true self. That’s important beyond just research, because it is a statement about inclusivity, which we should all be aware of. I think it’s good news that the tools we can use to study the influence of news at scale are finally within reach.




