
Easily clean up messy databases with fuzzy matching in R
One of the biggest challenges working with text data is the many different ways that people can enter the exact same information. A human knows that “St. Lucie, Florida,” “Saint Lucie, FL,” and “St Lucy, Florida” are probably all the same place, but a computer doesn’t.
“Fuzzy” matching pulls similarities between the letters in words and phrases to help group them together.
To begin, we will load our required libraries to work in R. You will need to install these packages first if you have not yet done so:
library(tidyverse)
## ── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.4 ✔ readr 2.1.5
## ✔ forcats 1.0.0 ✔ stringr 1.5.1
## ✔ ggplot2 3.5.2 ✔ tibble 3.3.0
## ✔ lubridate 1.9.4 ✔ tidyr 1.3.1
## ✔ purrr 1.1.0
## ── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
library(DT)
library(stringr)
library(stringdist)
##
## Attaching package: 'stringdist'
##
## The following object is masked from 'package:tidyr':
##
## extract
library(ggplot2)Bringing in the Data
We will be using a real data set: the schedule for the 2025 Investigative Reporters and Editors (IRE) conference.
Here we will download the IRE schedule, then save the session information as a data frame. Let’s first find all the unique session names.
IRE <- rio::import("https://schedules.ire.org/ire-2025/ire-2025-schedule.json")
sessions <- as_tibble(unlist(str_split(IRE$track, ",")))
sessions <- sessions %>%
group_by(value) %>%
summarize(total=n()) %>%
rename(session_track=value) %>%
arrange(desc(total))
unique(sessions$session_track)## [1] "Broadcast"
## [2] "Reporting and writing strategies"
## [3] "Beat reporting"
## [4] " Beat reporting"
## [5] "Tools & Tech"
## [6] " Public records"
## [7] " Story ideas"
## [8] "Beginner"
## [9] "Story ideas"
## [10] " Reporting and writing strategies"
## [11] "Educators"
## [12] "International"
## [13] " Networking"
## [14] ""
## [15] " Criminal legal system"
## [16] "Managing & Editing"
## [17] "Public records"
## [18] " Data analysis"
## [19] "\"Equity - inclusion - accessibility\""
## [20] "Audio/radio"
## [21] "Business"
## [22] "Career advice"
## [23] " Audio/radio"
## [24] "50th Anniversary"
## [25] "AI"
## [26] "Climate"
## [27] "Criminal legal system"
## [28] " Broadcast"
## [29] " Tools & Tech"
## [30] "Attacks on the press"
## [31] "Data analysis"
## [32] "Deep dive"
## [33] " \"Equity - inclusion - accessibility\""
## [34] " Research"
## [35] " Security"
## [36] " Students"
## [37] "Advanced"
## [38] "Freelance"
## [39] "Intermediate"
## [40] "Networking"
## [41] " AI"
## [42] " Attacks on the press"
## [43] " Beginner"
## [44] " Career advice"
## [45] " Data viz"
## [46] " Local news"
## [47] "Employment"
## [48] "Gender & reproductive rights"
## [49] " 50th Anniversary"
## [50] " Business"
## [51] " International"
## [52] "Data viz"
## [53] "Local news"
## [54] " Advanced"
## [55] " Employment"
## [56] " Gender & reproductive rights"
## [57] " Managing & Editing"
## [58] "Students"Some of these are not typed in exactly right, so we get separate categories where we only wanted one. “Beat reporting” and “ Beat reporting” were probably meant to be the same category! But an errant space after the quotation mark in the second instance makes them different to a computer.
Fuzzy matching
We can find other similar entries with mistakes by doing some fuzzy matching.
First, we’ll create a vector of the names. Then, we’ll create a function to categorize similar names based on a threshold we set. You can play with the threshold to have it be more or less strict (i.e., more or fewer letters in common).
# Sample vector of names
names_vector <- sessions$session_track
# Function to categorize similar names
categorize_names <- function(names_vector, threshold = 0.2) {
# Create an empty vector to store the labels
labels <- rep(NA, length(names_vector))
# Initialize the label counter
label_counter <- 1
# Loop through each name in the vector
for (i in 1:length(names_vector)) {
if (is.na(labels[i])) {
# Assign a new label to the current name
labels[i] <- label_counter
# Compare the current name with the rest of the names
for (j in (i + 1):length(names_vector)) {
if (stringdist(names_vector[i], names_vector[j], method = "jw") < threshold) {
# Assign the same label to similar names
labels[j] <- label_counter
}
}
# Increment the label counter
label_counter <- label_counter + 1
}
}
return(labels)
}
# Categorize the names and create a new vector with labels
name_labels <- categorize_names(names_vector)
# Print the original names and their corresponding labels
categories <- data.frame(Name = names_vector, Label = name_labels)
datatable(categories)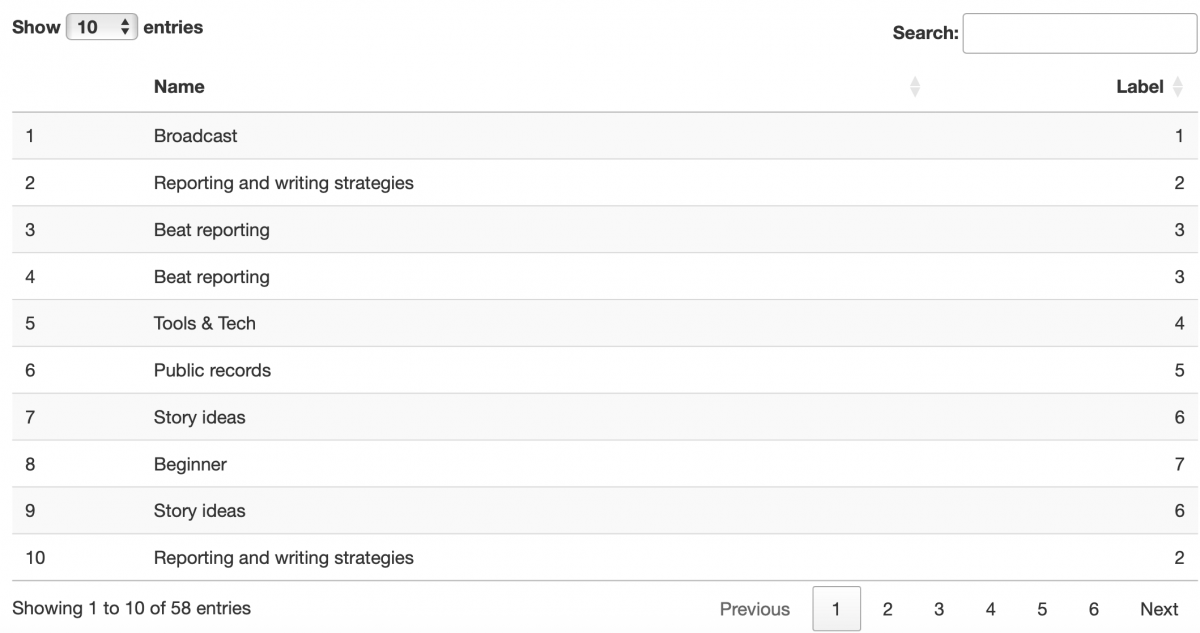
Each category now has a label. This is just a random number we assigned. We can now see “Beat Reporting” and ” Beat Reporting” are both in the same category (3).
But here we find a mistake! “ AI” is category 30 and “AI” is in category 20. From a human point of view, these are indistinguishable. But from a computer point of view, the former differs from the latter by 33%!
So we will fix this manually:
categories <- categories %>%
mutate(Label=ifelse(Name %in% c(" AI","AI"),20,Label)) #We could also have chosen 30 for bothHow many categories do we have versus how many labels?
length(unique(categories$Name))
## [1] 58
length(unique(categories$Label))
## [1] 33Looking at how the computer fuzzy matched these
Pro tip: always double-check your fuzzy matching to make sure the computer did it right. This is an extremely simple example and could probably have also been done just by trimming whitespace. But this is a really handy tool especially for matching up proper names. Longer names like “Cincinnati,” “Philadelphia,” and “Schuylkill” will never all come in perfectly!
We’re just checking here to make sure that each category has one label. And also so we can eyeball this and make sure it’s okay.
categories_with_labels <- categories %>%
group_by(Name,Label) %>%
summarize(Total=n()) %>%
arrange(desc(Label))## `summarise()` has grouped output by 'Name'. You can override using the
## `.groups` argument.datatable(categories_with_labels)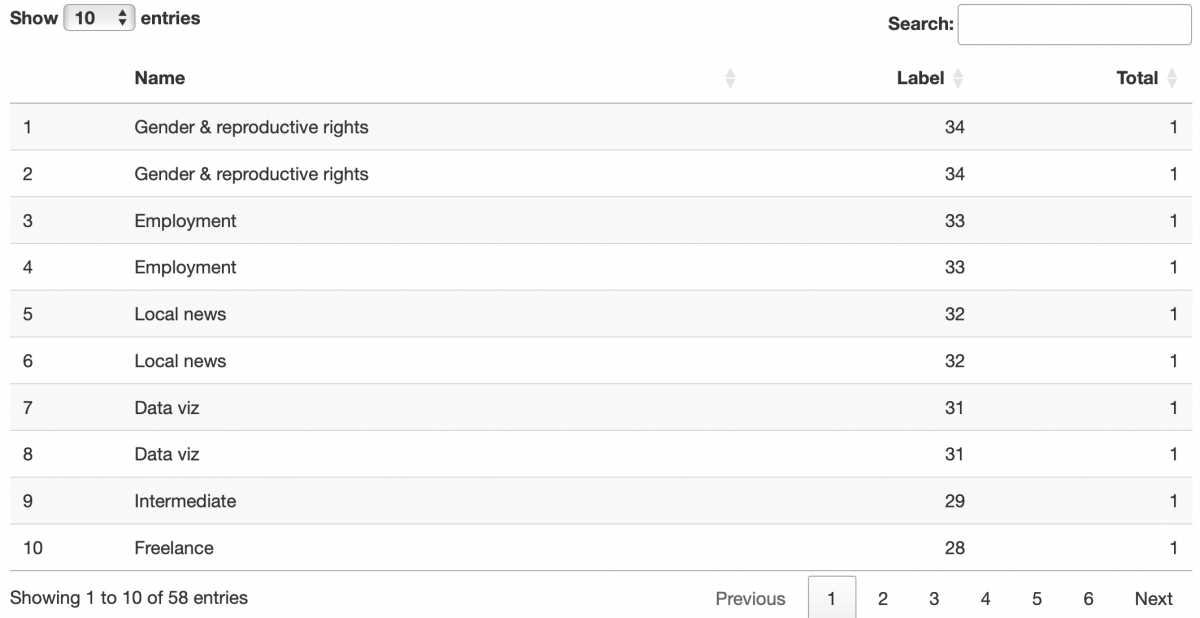
Now we’re going to concatenate each similar category with the same label.
categories_with_labels <- categories_with_labels %>%
group_by(Label) %>%
summarise(across(everything(),
~ paste(na.omit(.x), collapse = ", ")))
#.x inside the lambda represents each column’s values
DT::datatable(categories_with_labels)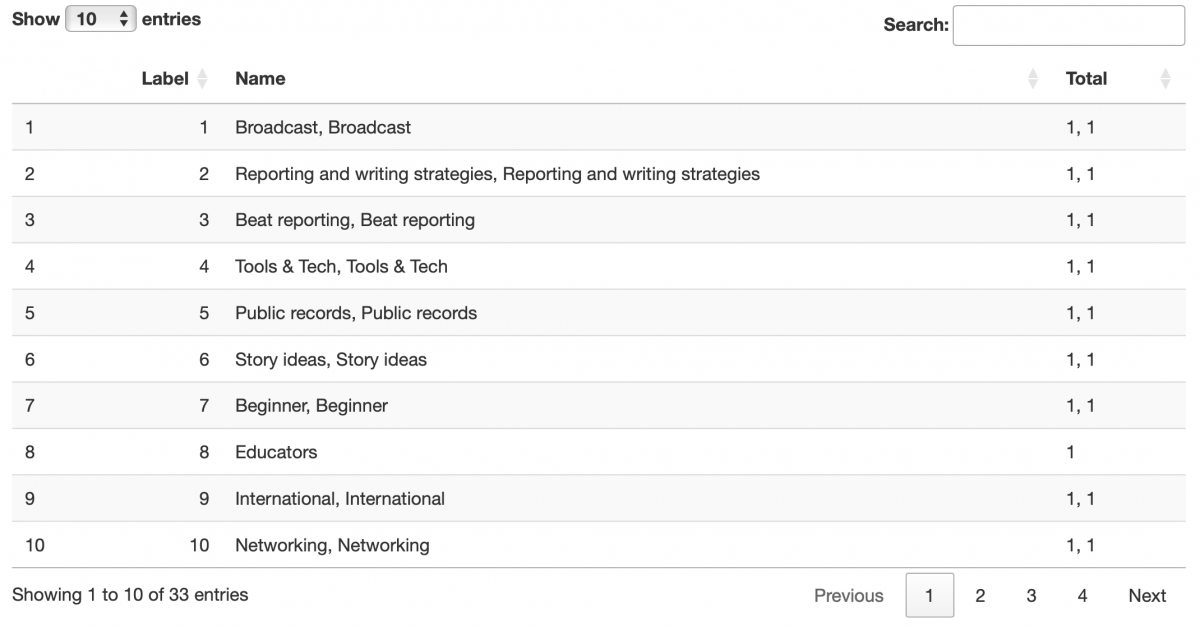
Now we are going to match this data back up with our session data:
sessions <- sessions %>%
mutate(category_number= categories$Label[match(sessions$session_track,categories$Name)])
sessions <- sessions %>%
mutate(combined_category=categories_with_labels$Name[match(sessions$category_number, categories_with_labels$Label)])
sessions <- sessions %>%
mutate(track=sub(",.*", "",combined_category))
sessions <- sessions %>%
arrange(desc(total))
DT::datatable(sessions)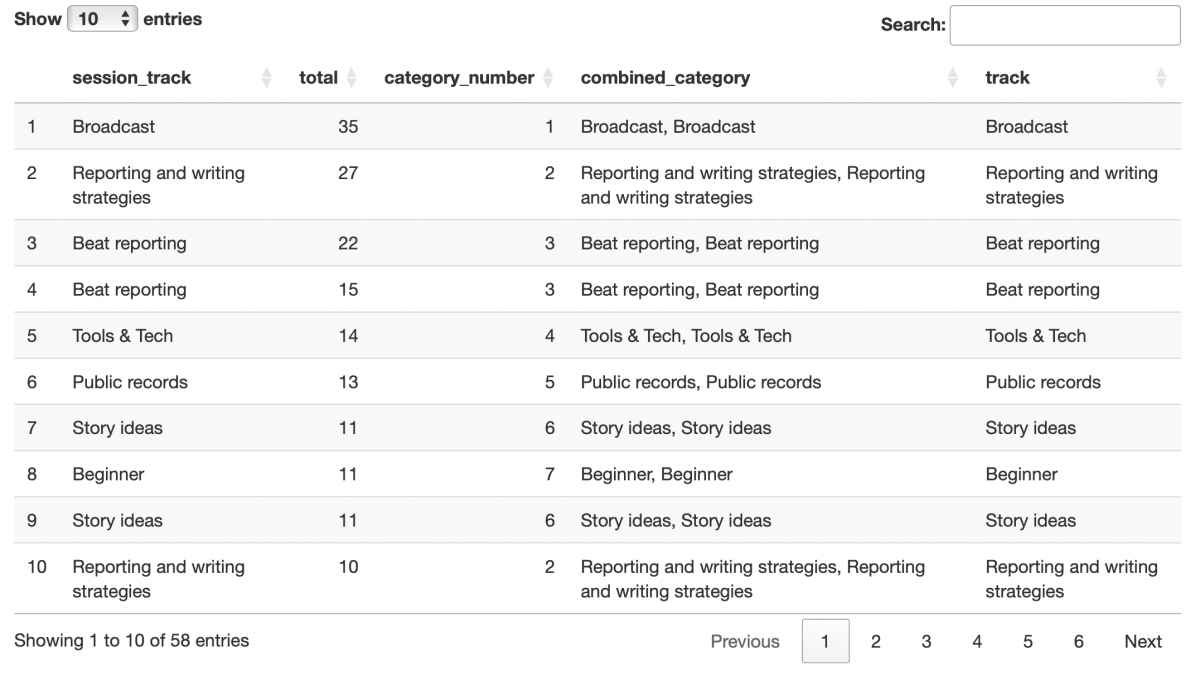
Visualizing the Results
What types of sessions will there be?
sessions %>%
group_by(combined_category) %>%
summarize(total=sum(total)) %>%
ggplot( aes(reorder(combined_category,-total),total))+
geom_col()+
geom_text(aes(label = after_stat(y)), stat = "summary",fun = "sum", vjust = -0.5, size = 10)+
theme(axis.text.x = element_text(angle = 75, vjust= .5, size = 20), axis.text.y = element_text(size = 20))+
theme(legend.position = "none")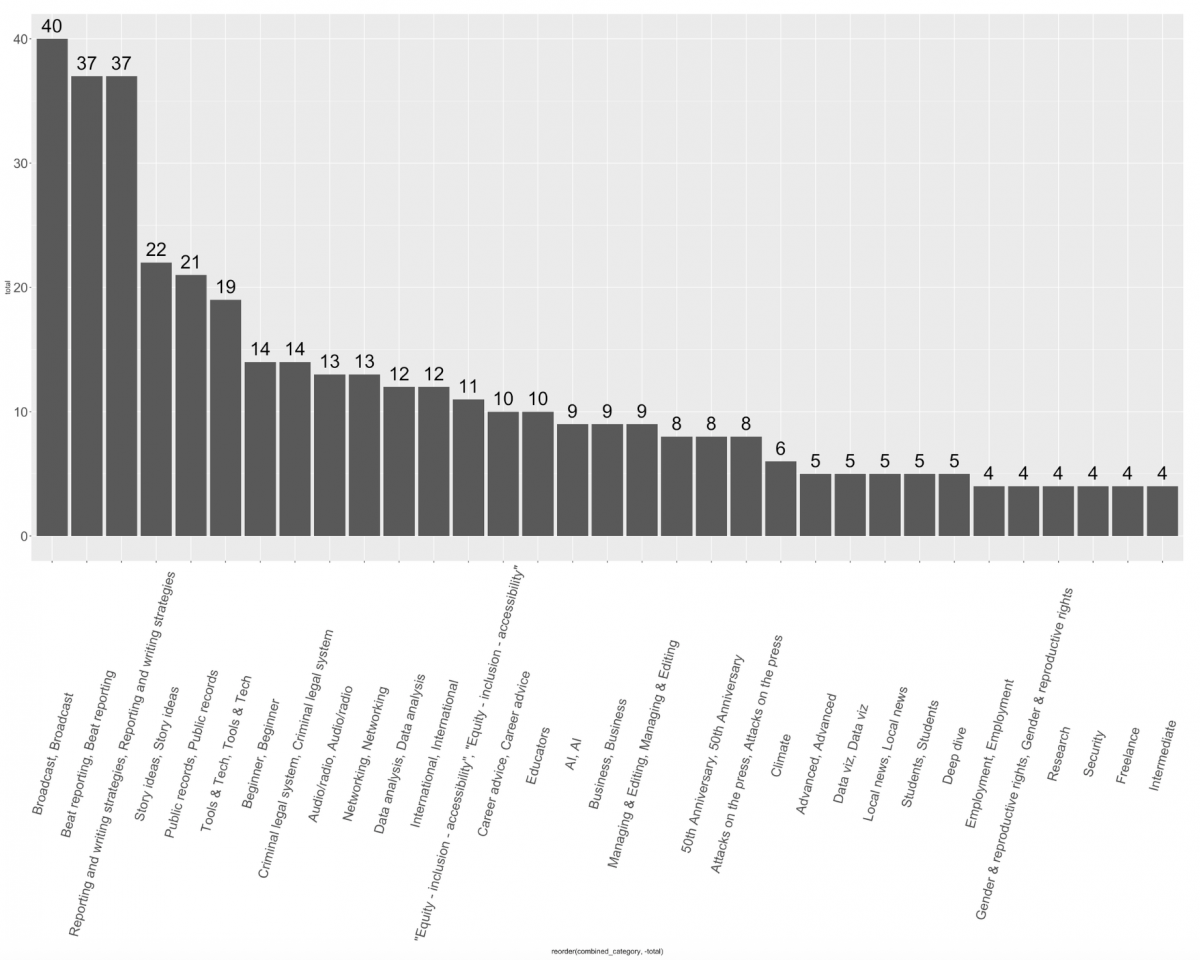
Final Thoughts
There are also some really great AI tools out there for fuzzy matching. The method in this tutorial is a bit cheaper and more environmentally friendly, but use whatever tool works for your project. Even with — and especially with — AI, remember to always double-check the results!

- How to Analyze bluesky Posts and Trends with R - November 4, 2025
- Easily clean up messy databases with fuzzy matching in R - September 16, 2025
- How to use R to analyze racial profiling at police stops - November 21, 2023


Thanks for this! I’ll definitely give it a try!