How to use Python to scrape for deleted government web pages
Every day, countless government web pages quietly disappear. Policies, reports and datasets once accessible to the public now show “Page Not Found.” Curious about what kind of pages have been removed, I took the Department of Justice (DOJ) as a test case, to recover the missing pieces of the once discoverable public record. We’ll be using Akash Mahanty’s wayback.py Python code to help us.
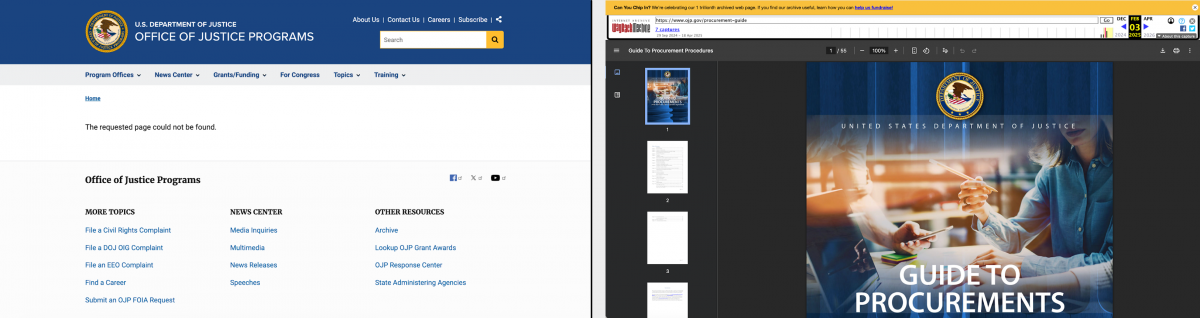
A page has been removed from the Office of Justice Programs (OJP) site, above left. Using the Wayback machine API, I found an archived copy, a document related to DOJ procurements, above right.
My starting point is the site map, an XML file that search engines can use as a roadmap to discover and crawl. Site maps give us a glance at an index of all the live pages on a website. The OJP keeps it at https://www.ojp.gov/sitemap.xml.
However, a sitemap only tells us about the current status of a site. If a sitemap is well-maintained, the entry of each URL is supposed to be functional. Then how can we detect pages that used to exist but are now gone?
That’s where the Web Archive, or Wayback Machine comes in. The digital archive allows us to view how a site looked at different points in time. We might put the sitemap in Wayback to get an archived copy from a given date we’re looking for, in that way, we would be able to capture a snapshot of all the URLs that were alive at the moment. Then by checking the current status of each URL, we can find which pages have since disappeared. Finally, using Wayback Machine APIs, we can extract the archived snapshots of those missing pages.
Now that we have a rough plan of the execution process, let’s take the page one of the site map of the OJP, captured on Jan 31, a list of 2000 URLs as a test. We’ll rely on packages Requests, BeautifulSoup and Wackbackpy to realize the idea.
Can you guess how many URLs disappeared? (Scroll down to the end of part 1 to see the answer!)
Let’s start coding.
First, make sure requests and lxml packages are installed. Open terminal and run:
pip install requests
pip install lxmlCreate a new folder named wayback_project to store further files we will create. In the example below, we’re creating it in the “Documents” folder of a Mac user.
mkdir /Users/Your User Name/Documents/wayback_projectNext, we create a Python script file. we’ll call it “ojp_status_check” and use it to place the code.
nano ojp_status_check.pyPaste all the code for finding missing pages, pages that return a 404 error code, into this new file. When done, press Crtl + o to save the file (the letter “o,” not the zero), Enter, and Crtl + X to exit. Run the file. If everything goes well we will eventually get a list of broken web pages.
python ojp_status_check.pySpotting 404 Pages
Now turn to Python code. We will want to install the following packages: requests for visiting the webpage, BeautifulSoup for parsing and scraping URLs in an XML file, csv for saving URLs in a CSV file, and ThreadPoolExecutor for conducting multiple tasks concurrently since we have thousands of requests.
import requests
from bs4 import BeautifulSoup
import csv
from concurrent.futures import ThreadPoolExecutor, as_completed
response = requests.get( "https://web.archive.org/web/20250131213030/https://ojp.gov/sitemap.xml?page=1",
timeout=15
)
response.raise_for_status()Parse the page 1 of the site map of OJP with BeautifulSoup. We may want to get instant feedback to see if the code runs well so we print the count of URLs, which is supposed to be 2000.
soup = BeautifulSoup(response.text, "lxml-xml")
loc_tags = soup.find_all("loc")
urls = [tag.text.strip() for tag in loc_tags]
print(f"Found {len(urls)} URLs to check.")Check each URL’s status. If the server responds normally, we put it into the catalog as “OK”. If the server returned an error code, >= 400, we categorize it as a “Broken” page. Otherwise, we put it in “Error” when a timeout or connection error happens. Here I’m filtering and saving only broken URLs to simplify the results.
def check_url(url):
try:
resp = requests.head(url, timeout=10, allow_redirects=True)
code = resp.status_code
if 200 <= code < 400:
return url, "OK", code
else:
return url, "Broken", code
except requests.exceptions.RequestException:
return url, "Error", None
results = []
with ThreadPoolExecutor(max_workers=20) as executor:
futures = [executor.submit(check_url, url) for url in urls]
for future in as_completed(futures):
results.append(future.result())
broken_only = [r for r in results if r[1] in ("Broken", "Error")]
with open("ojp_page1_status_broken.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["URL", "Status", "HTTP_Code"])
writer.writerows(broken_only)Then print our final summary and check how many URLs turn out to be broken.
ok = sum(1 for r in results if r[1] == "OK")
broken = sum(1 for r in results if r[1] == "Broken")
error = sum(1 for r in results if r[1] == "Error")
print(f" OK: {ok}")
print(f" Broken: {broken}")
print(f" Error: {error}")
print("Saved broken URLs to ojp_page1_status_broken.csv")Now we finish the code for finding non-existent pages. Here’s the test result. Does it come close to your guess?
- OK – Pages that are still available: 1989
- Broken – Pages that have been taken down: 11
- Error: 0

Bring 404 Pages Back into Light
With these links pointing to vanished pages, our next step will be dealing with the WayBack Machine API to reveal their historical copies.
Install the package waybackpy in terminal. As the developer writes, the usage of waybackpy is “a Python wrapper for the Wayback Machine API, allowing you to interact with the Wayback Machine to retrieve archived web pages.”
pip install waybackpynano ojp_page1_snapshots.py
python ojp_page1_snapshots.pyHere starts the second part of our Python code where we’ll extract snapshots of missing pages from the Wayback Machine.
import csv
from waybackpy import WaybackMachineAvailabilityAPI
broken_urls = []
with open("ojp_page1_status_broken.csv", newline="", encoding="utf-8") as f:
reader = csv.DictReader(f)
for row in reader:
broken_urls.append(row["URL"])
user_agent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"Use api.near() function to find the closest archived version.
def get_snapshot(url):
try:
api = WaybackMachineAvailabilityAPI(url, user_agent)
archive = api.near()
return url, archive.archive_url, archive.timestamp
except Exception:
return url, None, NoneLoop through each URL and collect results. Save all results to a new CSV. ➡️click to see my final results.
results = []
for url in broken_urls:
print(f" Checking {url} ...")
result = get_snapshot(url)
results.append(result)
with open("ojp_page1_wayback_snapshots.csv", "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["URL", "Archive_URL", "Timestamp"])
writer.writerows(results)
print(f" Saved {len(results)} entries to ojp_page1_wayback_snapshots.csv")By parsing the sitemap, filtering out broken links and pulling their archived snapshots, we can trace the fading footprints of a web like Sherlock Holmes following the clues of what once was. Thanks to wayback APIs this search no longer has to be manual; instead, we do it programmatically. Try it yourself and see what pages you can bring back!

- How to use Python to scrape for deleted government web pages - October 28, 2025
- Breaking a New Dawn: Investigative Journalist Chai Jing’s New Chapter - June 8, 2024