
Six fascinating projects from the 2019 Computation + Journalism Symposium in Miami
How often is social media used as a source in news stories? Can a decision-tree algorithm generate tens-of-thousands of 250-word stories? And what is belief-driven data journalism?
Those questions lie at the heart of some of the research projects at the intersection of computational tools and journalism presented last weekend at the 2019 Computation + Journalism Symposium held at the University of Miami and sponsored by the Knight Foundation. Below, we rounded up a few of the projects we found particularly promising.
How to generate 40,000 articles in five minutes
The Swiss media company Tamedia presented their findings from Tobi, a decision-tree algorithm that’s capable of generating tens-of-thousands of articles in minutes. Tobi’s 250-word stories are created using reporter-generated templates. The algorithm was responsible for dragging and dropping in collected data in order to better personalize local content.

What did we learn? Automation in newsrooms can be valuable if you have a long-tail audience, and readers have responded positively to automated content in the past. But who should byline a piece if a reporter and a robot have both worked on it?
Getting to the Core of Algorithmic News Aggregators
Leveraging crowdsourced auditing, researchers at Northwestern University endeavored to get to the bottom of the Apple News trending stories algorithm. The aim of the research was to determine what level of customization the trending stories algorithm supported from user to user by collecting data from Amazon Mechanical Turk and through their own semi-automated data collection system.
What did we learn? While Apple’s handpicked top stories showcase a wide range of news sources, their algorithm chose its stories from a considerably more limited pool. It also skews more heavily toward soft news related to entertainment, sports and celebrities.
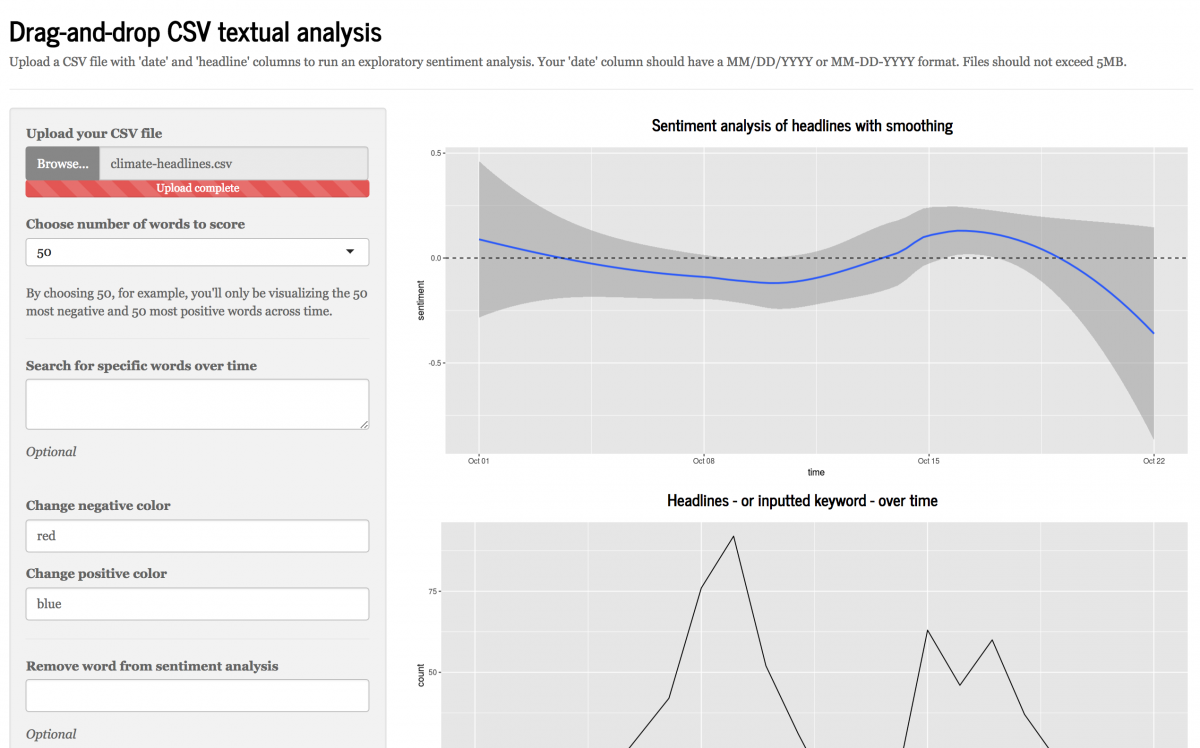
Newsroom Textual Analysis and Visualization Tools Built With R Shiny
While word cloud visualizations and similar types of simple tools are widely available on the web, the more sophisticated textual analysis software and code unfortunately remain the domain of experts and users of languages like R and Python. That’s why we at Northeastern University’s School of Journalism decided to develop a suite of apps that allow any user – journalist, researcher, layperson – to drop in a text file or spreadsheet and harness the power of R’s textual and sentiment analysis packages through public-facing R Shiny apps.
What did we learn? Sentiment analysis is frequently misunderstood and these apps provide some transparency into how those scores are calculated. These apps, though still only prototypes, point to the possibility of a broader ecosystem of similar deadline-friendly apps for newsrooms that could provide them with greater analytical power and higher-level insights, specifically around textual and sentiment analysis of political speeches or social media ads, for instance.
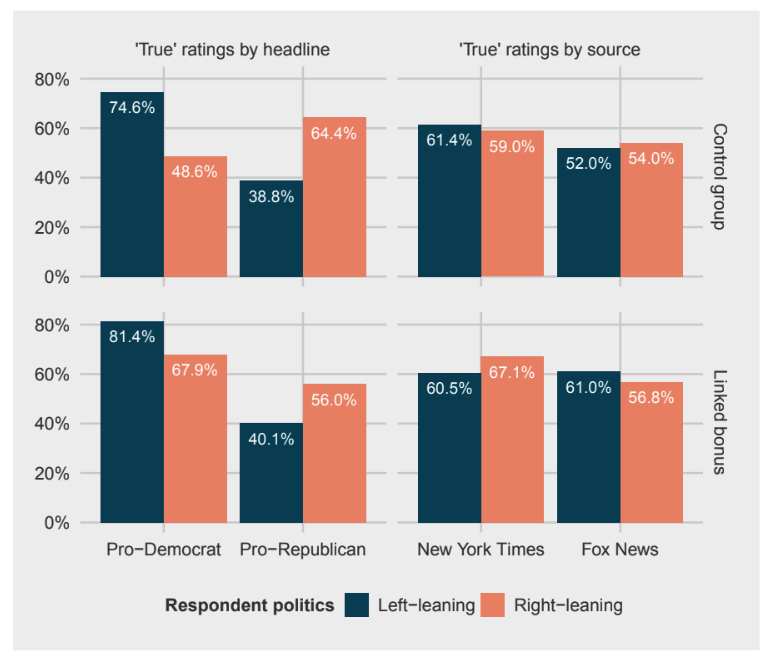
The Role of Source and Expressive Responding in Political News Evaluation
Researchers from Cornell University, Cornell Tech and Technion wanted to determine how strongly the source of a news story might affect a reader’s trust in that story. Respondents evaluated multiple headlines from multiple news sources, and were asked whether they believed the headline to be credible.
What did we learn? Based on this admittedly limited pool of respondents, it seemed that subjects were more likely to believe headlines that aligned with their own personal politics, and that the political leanings of a headline impacted credibility more than the source itself did.
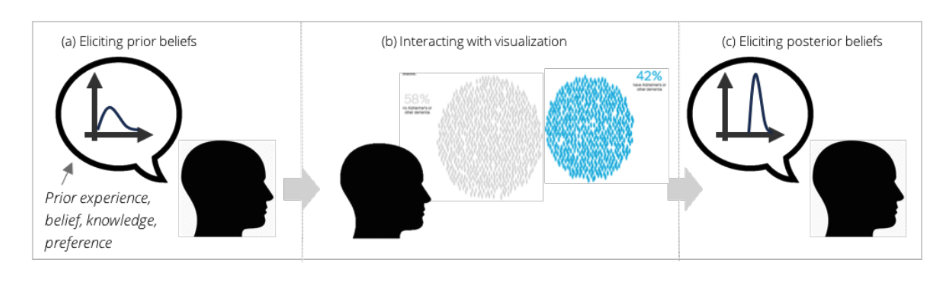
Belief-Driven Data Journalism
This study from Northwestern University proposes that belief-driven data journalism results in stronger reader engagement. They looked at four case studies centered around four different news stories, with each representing key data in different ways. Using pre-existing psychological research, they considered how different visualizations might be interpreted by the average reader, and they used that information to inform their development of a tool that generates reader-facing belief-driven visualizations.
What did we learn? Belief-driven data journalism is a ripe area of opportunity. Future research, possibly involving more robust methods of input, such as voice input, will provide more insight into how direct interaction between readers and data might affect the reader’s engagement and beliefs.
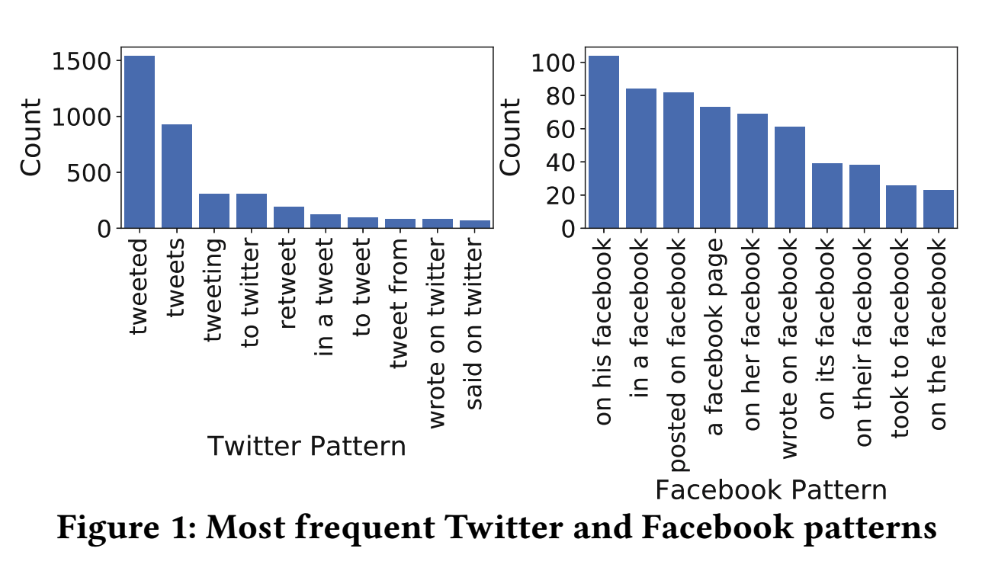
A Large-scale Study of Social Media Sources in News Articles
Researchers at the University of Oklahoma and the University of Mississippi examined approximately 60,000 news articles to audit the usage of social media as a source. In a country where tweets from the president often drive news coverage, they were interested in seeing how often these occasionally unreliable sources are cited in stories across a wide range of media outlets.
What did we learn? Social media content in news has doubled in the last five years, and is used more by small outlets than by mainstream outlets. Moreover, Twitter is preferred as a social media source more than Facebook is. Social media content is cited in political news across coverage of all sizes.
- How Northeastern researchers are visualizing the presidential debates - July 30, 2019
- Six tools showcased at NICAR 2019 that you should probably learn - March 26, 2019
- Six fascinating projects from the 2019 Computation + Journalism Symposium in Miami - February 6, 2019



