How to use ProPublica’s Congress API to see where senators stand on issues
Earlier this month, the Los Angeles Times used ProPublica’s Congress API to visualize the U.S. Senate’s response to President Donald Trump’s firing of FBI director James Comey. Released to the public last month, ProPublica’s Congress API, which was originally created by The New York Times, allows users to retrieve data on members, votes, bills, statements and other congressional goings-on.
The following tutorial uses the command line (Terminal on Mac) to query the Congress API for statements issued by senators on the firing of James Comey. Users must first request an API key from ProPublica here. (We got our API key within a day of asking).
Plan out your workflow
Before doing anything, it’s a good idea to write out your workflow, i.e. what your question is, what data you’re getting, where you’re getting it, and what you intend to do with it. Be as specific as possible! Note: We’re only simulating what the L.A. Times did, this is by no means the only way to query, explore and visualize data from the Congress API.
- Using the command line, query the “Congressional Statements by Search Term” endpoint for mentions of “Comey.”
- Save results into a JSON file.
- Convert JSON files into CSVs.
- Stack all CSVs into one master CSV.
- Open the master CSV, filter down by senators and by date, then click through to the URLs of each senator’s statement on Comey.
Make Congress API call through the command line
After reading through the API’s documentation, we know we’ll have to use the “Congressional Statements by Search Term” endpoint. According to the docs, the Congress API only allows users to retrieve 20 results at a time. The API supports pagination, though, meaning users can request multiple pages of results using the “offset” parameter. Notice the “?” and “&” at the end of the URL below; these are important.
Retrieve each page of 20 results individually from Congress API by supplying the API key – which will be emailed to you – as well as the “comey” search term by typing this into the command line:
curl -H "X-API-Key: MY_KEY_HERE" "https://api.propublica.org/congress/v1/statements/search.json?query=comey&offset=0" > file.json
To get back to a time before Comey’s firing, which happened May 9, we need to run this 16 times, each time incrementing the offset by 20 (until you reach 300) and renaming the output JSON file accordingly (file1.json, file2.json, etc.). This is what the results should look like:

Convert JSON files to CSVs using csvkit
Install csvkit from the command line. (Csvkit, by the way, is very powerful. Learn more here.)
sudo pip install csvkit
Next, convert the JSON files to csvs by providing csvkit’s “in2csv” function with the key “results,” which is where your data is nested (see JSON image above).
in2csv --key results file2.json > file2.csv
One way to combine all the CSVs
Stack all csv files into one “master” csv by dumping all files into a new folder, navigate to that folder in Terminal using cd FOLDER_NAME_HERE and then running:
cat file1.csv file2.csv file3.csv file4.csv file5.csv file6.csv ... file16.csv > file_combined.csv
If you open up that csv, you’ll notice there are headers (url, date, title, etc.) every 20 rows. We could remove those manually in a program like Excel. But why not do it programmatically?
Remove headers from a CSV using the command line
To remove headers from file2.csv through file16.csv, dump all of those files (everything except file1.csv) into a directory, navigate to the directory in Terminal and then run:
for filename in $(ls file*.csv); do sed 1d $filename >> final.csv; done
Then move file1.csv into that same directory and combine it with final.csv using:
cat file1.csv final.csv > final_combined.csv
To sum up, files file2.csv through file16.csv have had their headers removed and then we’ve stacked those files with file1.csv which still has its header.
Open up your CSV
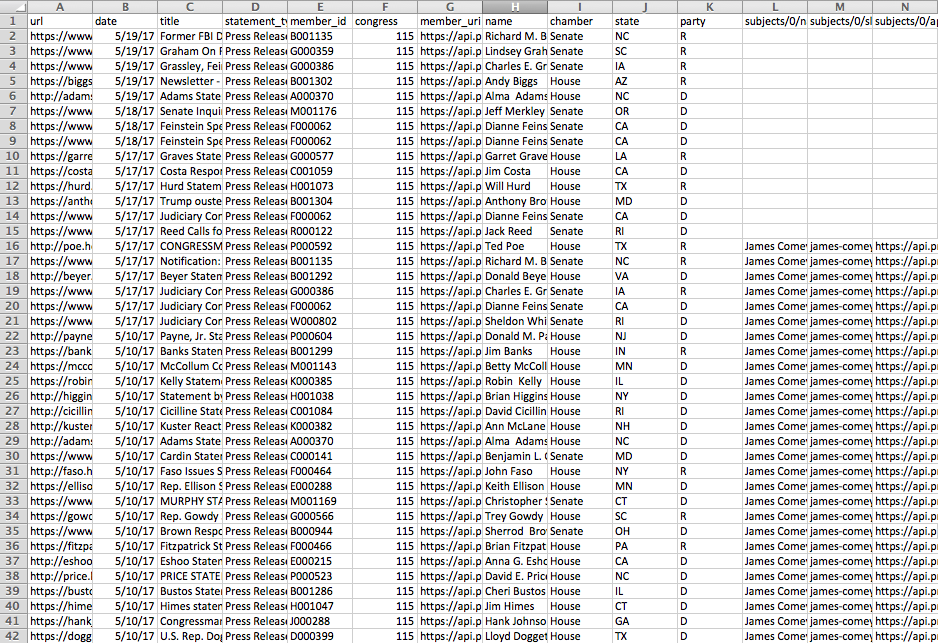
Look through the statements
According to Chris Keller and Priya Krishnakumar of the L.A. Times, the next step was a manual one. The two began reading through individual statements made by senators about Comey’s firing and ranked them along a spectrum: Willing to let the investigation play out, Noncommittal, Expressed concerns, Calls for a special prosecutor or investigation, No public statement. Below, a screenshot from their story.

We could emulate the L.A. Times‘ ranking system by creating a new column – “gist” for example – and ranking them using those phrases. Below, an example of a statement released on May 10 about Comey’s firing:

A shallow dive into the data
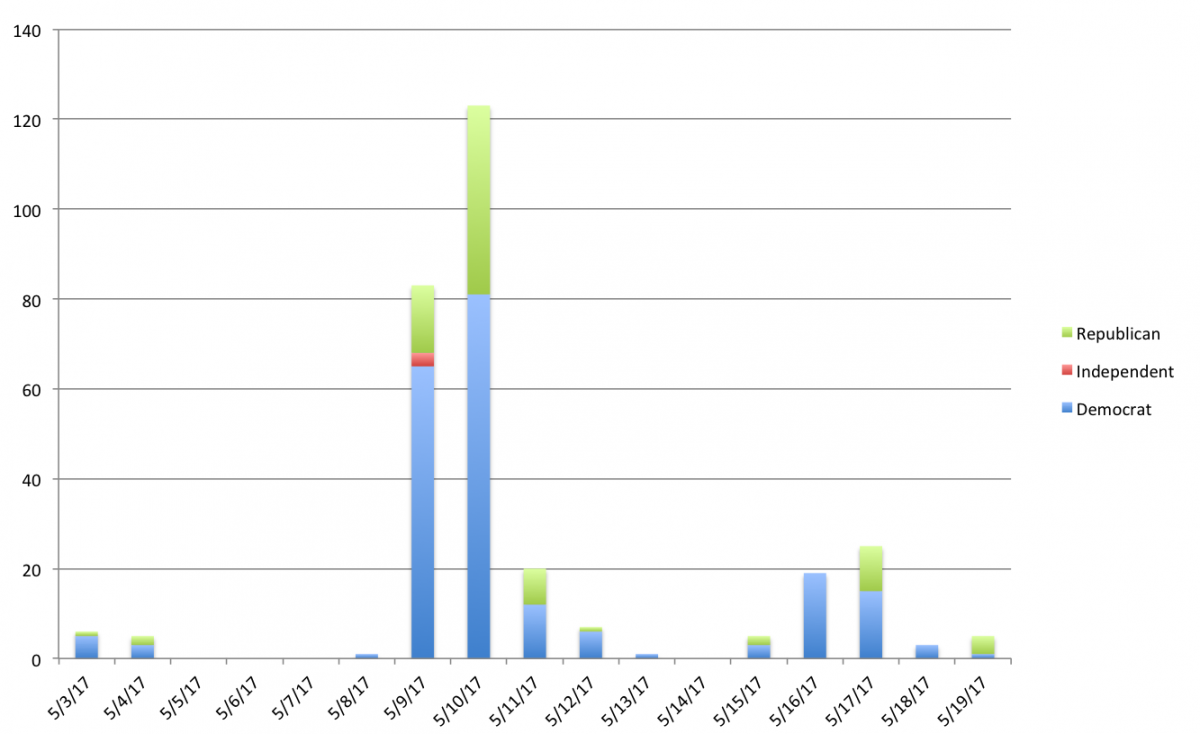
Using a pivot table with our final csv, we can reveal the spike of statements issued just after Trump fired Comey, which happened on the afternoon of May 9.
Statements about James Comey released by Congress in May 2017
Solving the pagination problem
The Congress API only allows you to retrieve 20 results per query, which is why we had to change the offset value to “paginate” through their results. But the process of having to download 17 JSON files is a bit time-consuming (~ 10 seconds each). Is there an easier way?
The following will retrieve the same results and save them all into one JSON file.
for ((i=0;i<=300;i+=20));
do curl -H "X-API-Key: MY_KEY_HERE"
"https://api.propublica.org/congress/v1/statements/search.json?query=MY_SEARCH_TERM_HERE&offset=$i";
done > file.jsonUnfortunately, this method introduces some extraneous JSON that ProPublica adds: (“status”:”OK”, “copyright”:”Copyright (c) 2017 Pro Publica Inc. All Rights Reserved.”, etc.). If anyone has suggestions to improve this, please send along!