
Carlos Scheidegger on why data science needs to be done humanely
The bias inherent in machine learning algorithms and other computer systems is an issue that concerns many industries, including journalism. For example, reporters such as Julia Angwin – formerly with ProPublica and now heading a news start-up The Markup – has done investigative work into machine bias against African Americans and other populations.
Earlier this month at Northeastern University, University of Arizona computer scientist Carlos Scheidegger gave a talk – aptly named “Data Science, Humanely” – about these very issues as part of Northeastern’s Data Visualization @ CCIS series.
“Our ability to automate things has far outpaced our ability to validate those things and to understand the consequence of those decisions,” Scheidegger warned, explaining that our data science infrastructure is inhumane. “We’ve created a world in which people can write these programs that are really hard to validate.” Scheidegger’s current research interests are in large-scale data analysis, information visualization and, more broadly, what happens “when people meet data.”
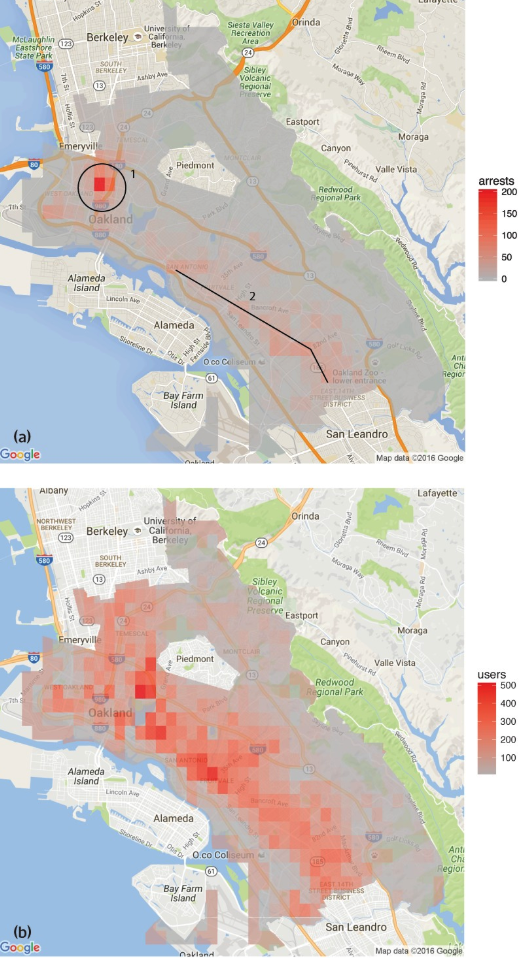
Scheidegger provided a real-world example to convey the potential consequences of these algorithm-training decisions. He pointed to a recent study by Kristian Lum and William Isaac, in which they examined how historical drug arrest data for regions of Oakland, Calif. could be used to direct policing using a computer program. To make policing more efficient, the data and program would then be used to allocate patrol officers to areas with presumably high drug usage.
But the distribution of drug arrests and distribution of estimated drug usage based on surveys did not match. Not only was there a notable difference between those distributions, the disparity also affected some populations more than others.
“This presumably unbiased complete data-driven decision is implemented in a way that ends up arresting twice as many black people as it should,” explained Scheidegger. “The long-range distribution is actually given entirely by the beginning state and nothing about what you expect it to be,” he said.
A way to mitigate this problem, Scheidegger said, is to instead update our computer model with crimes observed at a region where we do not go too often. “This is where communities like us [who are] academics have a role in keeping people who are deploying these systems in check,” he said.
Scheidegger ended on a cautionary note, saying the issue deserves a whole lot more thought. We’ve created a world in which we can make predictions based on data analysis but we are not careful about the effects they have on people who are the subjects or targets of this analysis.
Image: Wikimedia Commons.
- What I learned applying data science to U.S. redistricting - January 20, 2020
- How to build a heatmap in Python - February 18, 2019
- The future of machine learning in journalism - January 2, 2019



.jpg){kind=link}