Finding Embedded Tweets in Online News with Python
Seeing embedded tweets in an online news story has become quite normal. As a platform especially well suited to breaking news, Twitter is a favorite for journalists and politicians alike.
Researchers have taken on the question of the use of Twitter in news, leading to published studies and datasets. However, digital news norms continue to evolve, and after using existing solutions we started to suspect that many embedded tweets were being missed in the studies.
Embedded tweets allow you to take a tweet or a conversation and post it on your website or in a blog post. It has become a common approach to include social media content within a news story, usually by copying a short bit of HTML or Javascript supplied by the social media platform into your webpage. This then renders the embedded content in the style and branding of the source, allowing them to officially share content across the web.
To investigate and resolve this, we’ve created and released tweetfinder, a small new Python library that does a better job finding embedded tweets and mentions of Twitter in online news stories.

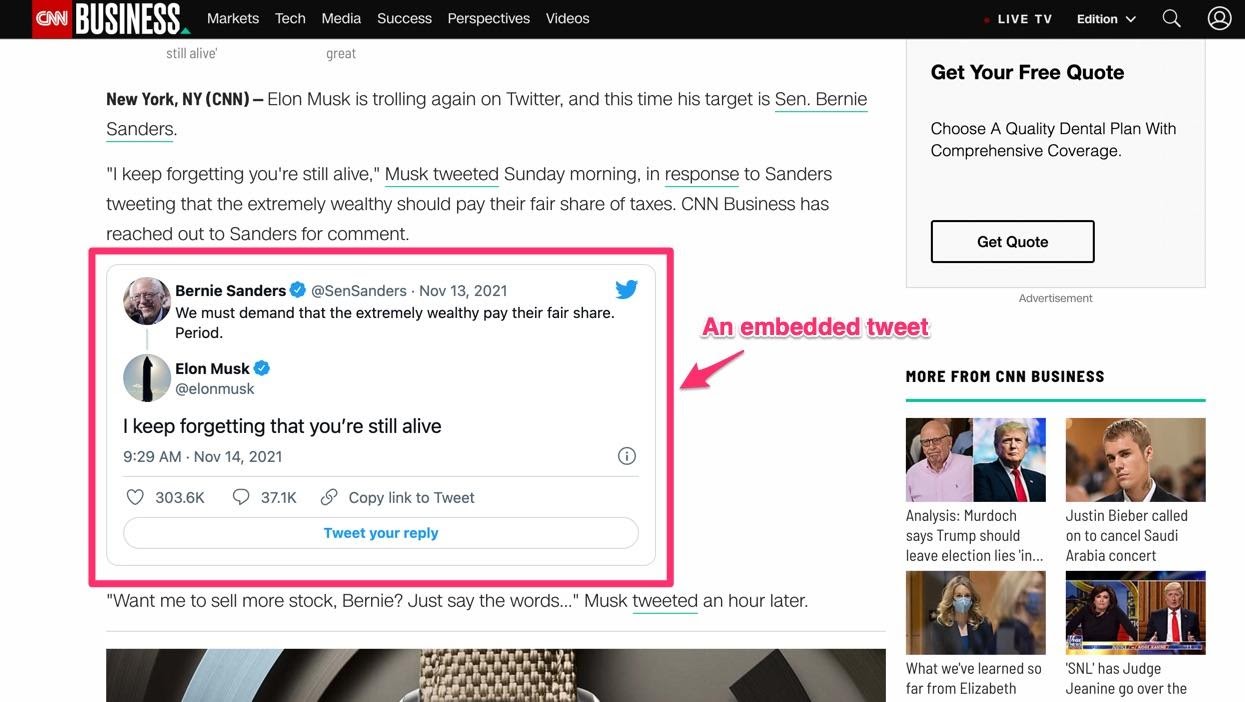
An example of a tweet embedded in an online news story
Why did we build this?
Academics are trying to understand these rapid changes in digital news norms. As the use of embedded tweets in news increases, some argue that it connects to larger trends of shifting authority and power in information dissemination online. If we want to understand and test these questions, we have to know that we’re collecting the underlying data as accurately as possible.
After using some other tools for solving this need, we found that existing solutions were missing embedded tweets in some articles. Curious as to why, we realized that some news sites weren’t following Twitter’s recommended approach precisely, and others were rendering their whole pages with Javascript. The most popular current library for finding tweets, Goose, doesn’t handle either of those cases.
Using It
Technically, “tweetfinder” is a Python package that parses HTML content for embedded tweets and mentions of twitter. You can give it a URL, or raw HTML, as input and it provides convenience methods to return lists of those two types of references it finds. You can process a news story like this:
from tweetfinder import Article
my_article = Article(url=”https://edition.cnn.com/2021/11/14/business/elon-musk-bernie-sanders-tweet/index.html”)
With an article object, you call my_article.list_embedded_tweets() to get a list with information about the embedded tweets:
[{‘tweet_id’: ‘1459891238384115722’,
‘username’: ‘elonmusk’,
‘full_url’: ‘https://twitter.com/elonmusk/status/1459891238384115722?ref_src=twsrc%5etfw’,
‘html_source’: ‘blockquote url pattern’}]
Or, if you call my_article.list_mentioned_tweets() you get a list of all the mentions of twitter in the article:
{‘phrase’: ‘tweeted’,
‘context’: ‘eached out to sanders for comment. “want me to sell more stock, bernie? just say the words…” musk tweeted an hour later. musk ended the week selling a grand total of $6.9 billion worth of tesla shares. tha’,
‘content_start_index’: 284},
Under the Hood
To find more of the tweets embedded, we took a multi-pronged heuristic approach. Our pipeline begins with the HTML (parsed with the BeautifulSoup library), because the popular readability content extraction library removes tags we need as signals such as blockquotes. We then process the HTML tree using the following heuristics to locate any embedded tweets:
- Check all `blockquote` nodes for a class of “twitter-tweet” (the officially supported approach)
- Check all `blockquote` nodes for a child `a` node linking to twitter.com (because sometimes organizations don’t include the class attribute)
- Check all `div` nodes with a class attribute of “embed-twitter” (a pattern we saw on CNN and other major US news sites)
- Check any `div` nodes with a class attribute of “twitter-tweet-rendered” and extract the tweet from any child `iframe` node (a pattern we saw on a few Javascript-rendered websites)
We also used our library with selenium, an automation package that lets you control a “headless” web browser from code. Selenium lets us render a webpage with Javascript as if a browser was open, and then pull the generated HTML out, all from Python code. While that definitely takes more computer processing power and time to run, it does ensure more complete results.
Mentions of tweets, or paraphrases of Twitter content, are another approach news media take to integrating social media content into their news stories. Our library integrates prior keyword lists and expands them to allow us to find these types of mentions of twitter content. A clear limitation is that this approach currently only works for English language content; we use cld2 to detect the content language and raise an error if the user attempts to list mentions on non-English language articles.
Results
Combining all these approaches, in a sample of around 1000 articles we found about 30% more embedded tweets than Goose does. This is a noticeable difference, and one that matters when doing research into how online news sources are using embedded tweets. You can read more technical details about this analysis on our blog.
We’re currently putting this to work in our research in order to help us identify types of stories that rely on Twitter content, and track their use over time. For example, consider the “Twitter reaction” type of story – a short piece made up of a dozen or so embedded tweets about the same topic. Are these stories more common on digital native media sources vs. traditional print news? Has their frequency of use changed over time? Or consider how often tweets are mentioned a number of times in a news story. Is that frequency higher in news publications from states whose politicians are more active on Twitter? These types of questions are important to understanding the still emerging interplay between online news and Twitter. We hope tweetfinder contributes to our ability to understand this more accurately.
- Finding Embedded Tweets in Online News with Python - January 21, 2022



