How to collect tweets from the Twitter Streaming API using Python
Twitter provides a comprehensive streaming API that developers can use to download data about tweets in real-time, if they can figure out how to use it effectively. In this tutorial, we’re going to retrace the steps I took to set up a server to collect tweets about hate speech as they occur to create a dataset we can use to learn more about patterns in hate speech.
The first step is to apply for a Twitter Developer account. You will have to link to your Twitter account and write a brief summary of what you plan to do with the data you extract using the Twitter API. You should receive approval quickly, but unfortunately you can’t proceed with setup until your application is approved.
After you receive approval, you need to register your app. Within the Twitter Developer website, go to Apps and click “Create an app”. The page will ask you for more information about what your app will do and where it will be hosted.
Now that we have all of the administrative stuff taken care of, we can get to the code. For this example, I’m using the Tweepy library to handle some of the streaming logistics.
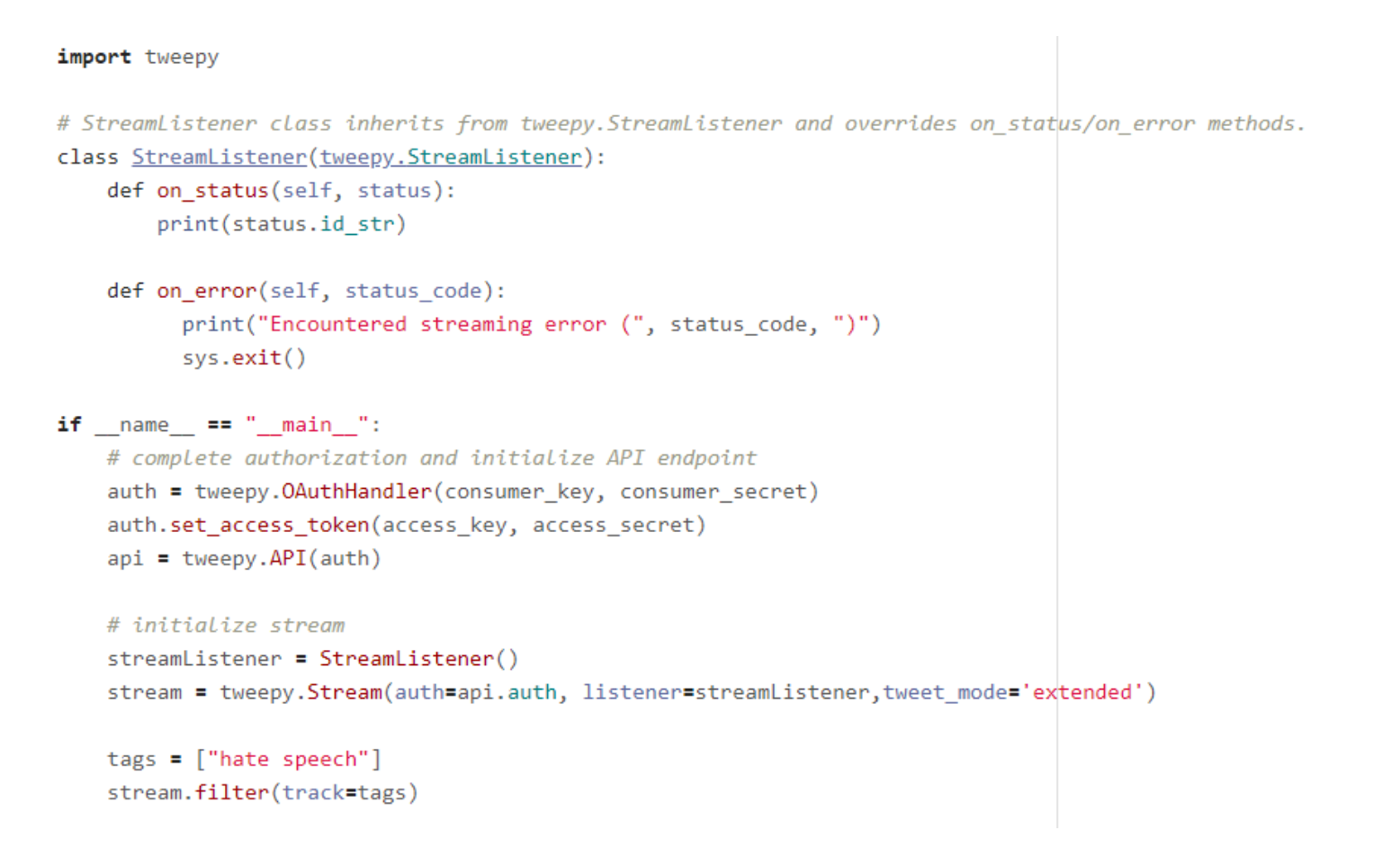
Step 1: In Python, import Tweepy and set up your authentication and stream listener with API keys. Here we’re using the authentication information Twitter provided when we registered our application.

Step 2: Create StreamListener class. In the same file, we’re going to create a new class called StreamListener that inherits from tweepy’s StreamListener class and overrides the on_status and on_error methods so that we can customize what we want to do with each tweet we encounter. For now, let’s just print the id of each tweet. We’ll add in more sophisticated functionality later.
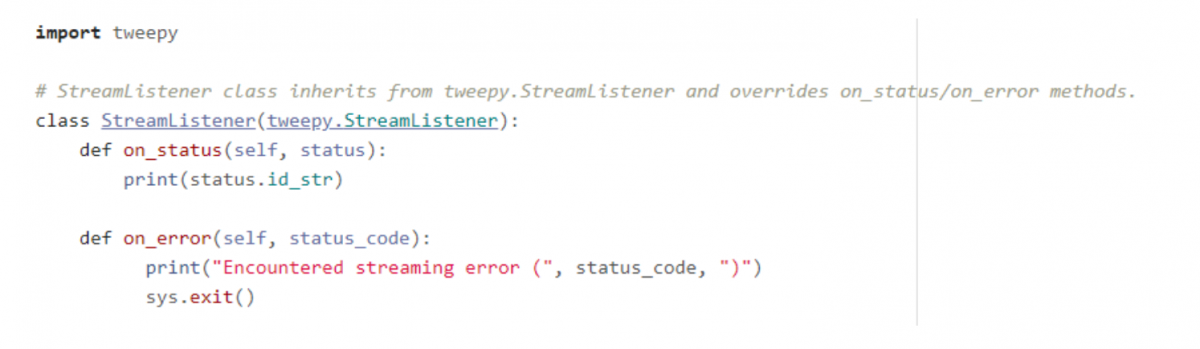
Step 3: Initialize stream with filters. Finally, we can start the stream by specifying the tags we want to use to filter tweets.
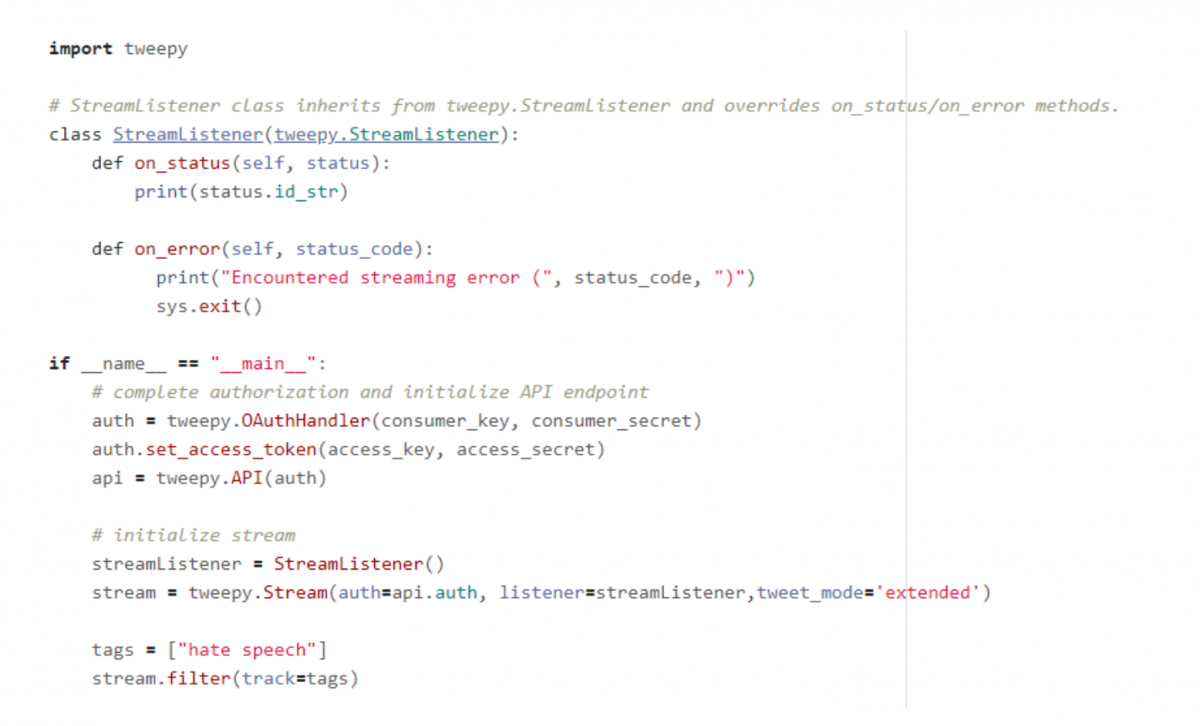
Step 4: Process and store data. We want to store the tweets we encounter in the stream so that we can refer back to it and perform offline analysis. Let’s log tweet data in a csv for now. (We’ll upload this file to a GitHub repository in Step 6 so that collaborators can access it!)
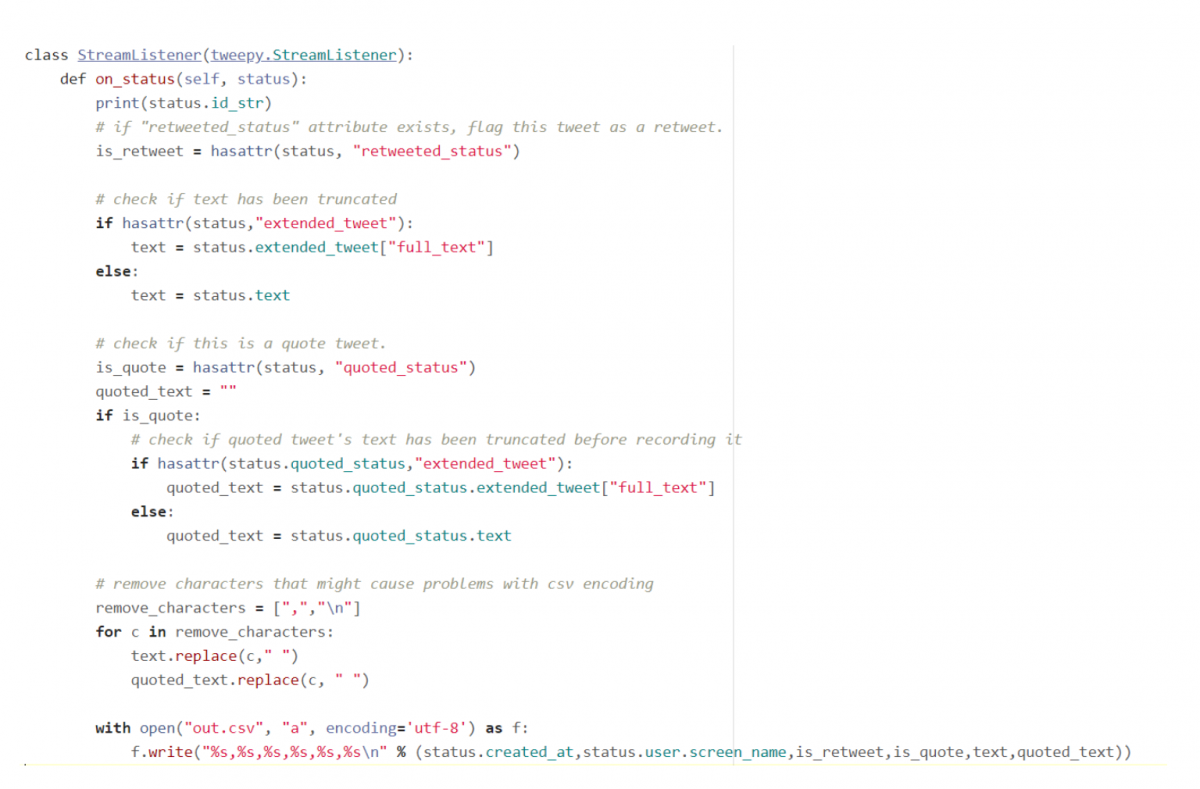
Step 5: Handling retweets, extended tweets, and quote tweets. When you run this code, you might notice the same text appearing over and over. In most cases this isn’t because of bots, but rather because one tweet is being retweeted over and over and the Twitter Streaming API doesn’t immediately distinguish between original tweets and retweets. To fix this, we have to look for an attribute called “retweet_status” in the status object. Let’s add a flag to indicate if the current tweet is a retweet or not.

To further complicate things, the API automatically truncates the text attribute of tweets longer than 140 characters. If you want to access the full text, which you probably will need if you’re doing any kind of natural language processing analysis on the data, you need to access the “extended_tweet” attribute of the tweet object. Let’s check for this attribute to make sure we’re getting the full text before recording each tweet.

Twitter has one more special case: the quote tweet. This occurs when a user retweets a post and adds a comment alongside the retweet. As before, this case is signified by a “quoted_status” attribute. Let’s flag quote tweets and store the text of the tweet that was quoted. We will also remove any characters that might cause problems with the csv encoding, like newlines and commas.
Step 6: Share with collaborators
There are a lot of ways you could share your Twitter datasets with collaborators, like Google Drive or Dropbox, but I’m going to use GitHub because it has a really good version control system and it’s easy to add collaborators. If you haven’t used GitHub before, I would suggest looking at a tutorial to familiarize yourself with the workflow.
At a basic level, GitHub allows you to make changes to project files on your computer and push those changes to a “master” version of the project that is hosted on a remote server. GitHub keeps track of all the changes you make, so it’s easy to revert back to previous versions if you make a mistake or accidentally overwrite a file. Also, GitHub allows multiple collaborators to edit the same file with lots of precautions to prevent anyone from accidentally deleting or changing important data or code.
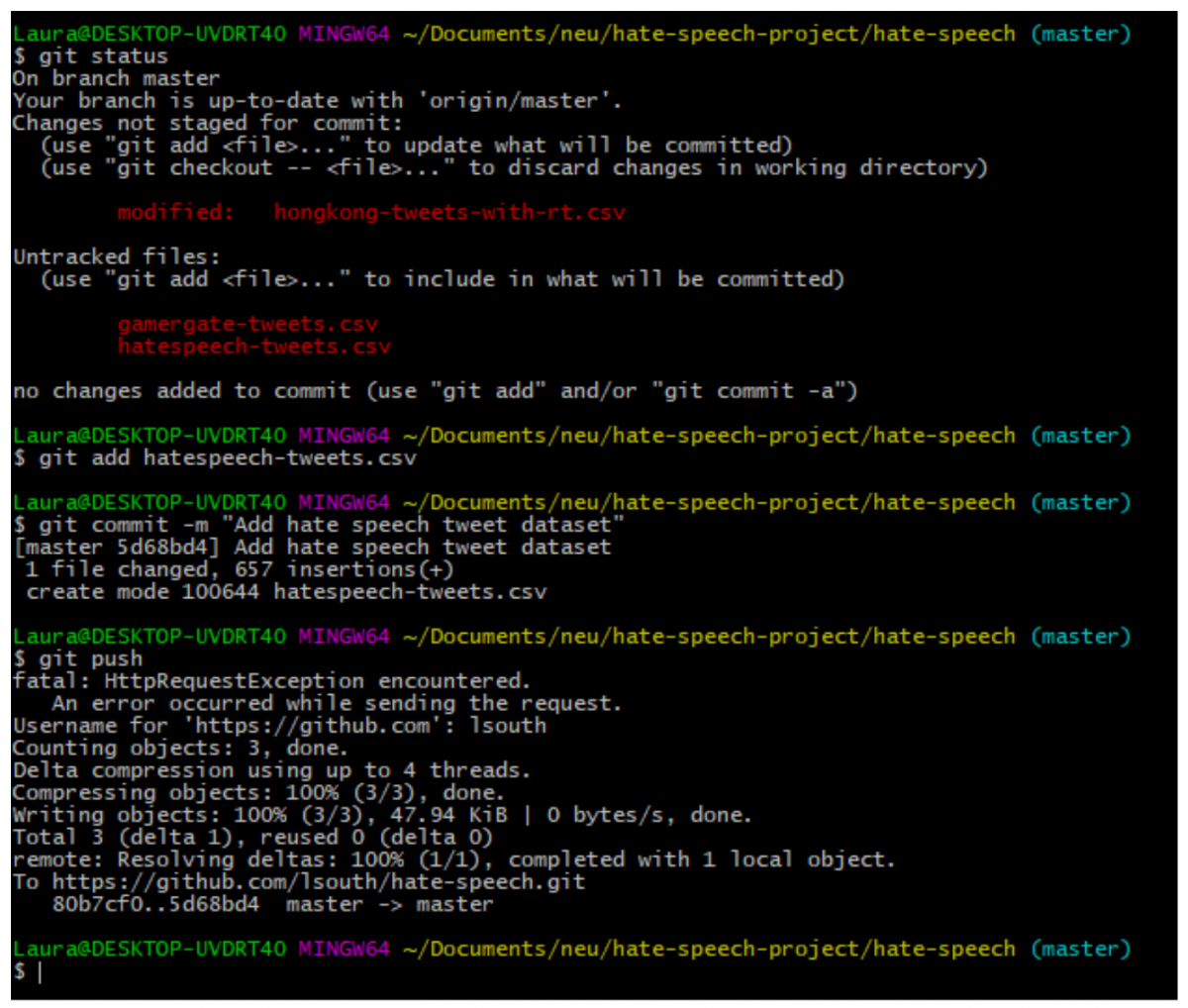
I have a GitHub repository called hate-speech and I want to push a file called “hatespeech-tweets.csv” where I recorded tweets with the keyword “hate speech.” I can use the following commands to add the file to my repository, commit the changes I made, and finally push it to the remote version of my repository, where it can be viewed and downloaded by collaborators.
We now have a functional program that listens for and records Twitter activity on any topic you’re interested in. There’s always room for improvement, like using a database to store the records we’re interested, examining different user and tweet data attributes, or conducting some rudimentary sentiment analysis on tweets as they come in, but this is a good starting point — you’re well on your way to incorporating live Twitter data in your application. Good luck!
import tweepy
# authorization tokens
consumer_key = "[insert your key here]"
consumer_secret = "[insert your secret here]"
access_key = "[insert your key here]"
access_secret = "[insert your secret here]"
# StreamListener class inherits from tweepy.StreamListener and overrides on_status/on_error methods.
class StreamListener(tweepy.StreamListener):
def on_status(self, status):
print(status.id_str)
# if "retweeted_status" attribute exists, flag this tweet as a retweet.
is_retweet = hasattr(status, "retweeted_status")
# check if text has been truncated
if hasattr(status,"extended_tweet"):
text = status.extended_tweet["full_text"]
else:
text = status.text
# check if this is a quote tweet.
is_quote = hasattr(status, "quoted_status")
quoted_text = ""
if is_quote:
# check if quoted tweet's text has been truncated before recording it
if hasattr(status.quoted_status,"extended_tweet"):
quoted_text = status.quoted_status.extended_tweet["full_text"]
else:
quoted_text = status.quoted_status.text
# remove characters that might cause problems with csv encoding
remove_characters = [",","\n"]
for c in remove_characters:
text.replace(c," ")
quoted_text.replace(c, " ")
with open("out.csv", "a", encoding='utf-8') as f:
f.write("%s,%s,%s,%s,%s,%s\n" % (status.created_at,status.user.screen_name,is_retweet,is_quote,text,quoted_text))
def on_error(self, status_code):
print("Encountered streaming error (", status_code, ")")
sys.exit()
if __name__ == "__main__":
# complete authorization and initialize API endpoint
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_key, access_secret)
api = tweepy.API(auth)
# initialize stream
streamListener = StreamListener()
stream = tweepy.Stream(auth=api.auth, listener=streamListener,tweet_mode='extended')
with open("out.csv", "w", encoding='utf-8') as f:
f.write("date,user,is_retweet,is_quote,text,quoted_text\n")
tags = ["hate speech"]
stream.filter(track=tags)- How to collect tweets from the Twitter Streaming API using Python - November 10, 2019




Ok, it was really interesting information, I also use data delivery from API https://twitter.sneakin.info/en/ – which is my personal project.
Dear Laura
I hope you are well. I was using your code to extract some information from twitter. The code runs for many hours and then i get an error similar to :
ProtocolError: (‘Connection broken: IncompleteRead(56 bytes read)’, IncompleteRead(56 bytes read))
Is there a way to avoid that error please? I replaced this piece of your code with this
def on_error(self, status_code):
#print(“Encountered streaming error (“, status_code, “)”)
#sys.exit()
if status_code == 420:
#returning False in on_data disconnects the stream
return False
but it did not help. How can i avoid hitting the error when the code runs for a long time? is there a way to pause the code for few minutes to avoid hitting the rate limit?
Thank you so much