
How to scrape Reddit with Python
Last month, Storybench editor Aleszu Bajak and I decided to explore user data on nootropics, the brain-boosting pills that have become popular for their productivity-enhancing properties. Many of the substances are also banned by at the Olympics, which is why we were able to pitch and publish the piece at Smithsonian magazine during the 2018 Winter Olympics. For the story and visualization, we decided to scrape Reddit to better understand the chatter surrounding drugs like modafinil, noopept and piracetam.
In this Python tutorial, I will walk you through how to access Reddit API to download data for your own project.
This is what you will need to get started:
- Python 3.x: I recommend you use the Anaconda distribution for the simplicity with packages. You can also download Python from the project’s website. When following the script, pay special attention to indentations, which are a vital part of Python.
- An IDE (Interactive Development Environment) or a Text Editor: I personally use Jupyter Notebooks for projects like this (and it is already included in the Anaconda pack), but use what you are most comfortable with. You can also run scripts from the command-line.
- These two Python packages installed: Praw, to connect to the Reddit API, and Pandas, which we will use to handle, format, and export data.
- A Reddit account. You can create it here.
The Reddit API
The very first thing you’ll need to do is “Create an App” within Reddit to get the OAuth2 keys to access the API. It is easier than you think.
Go to this page and click create app or create another app button at the bottom left.
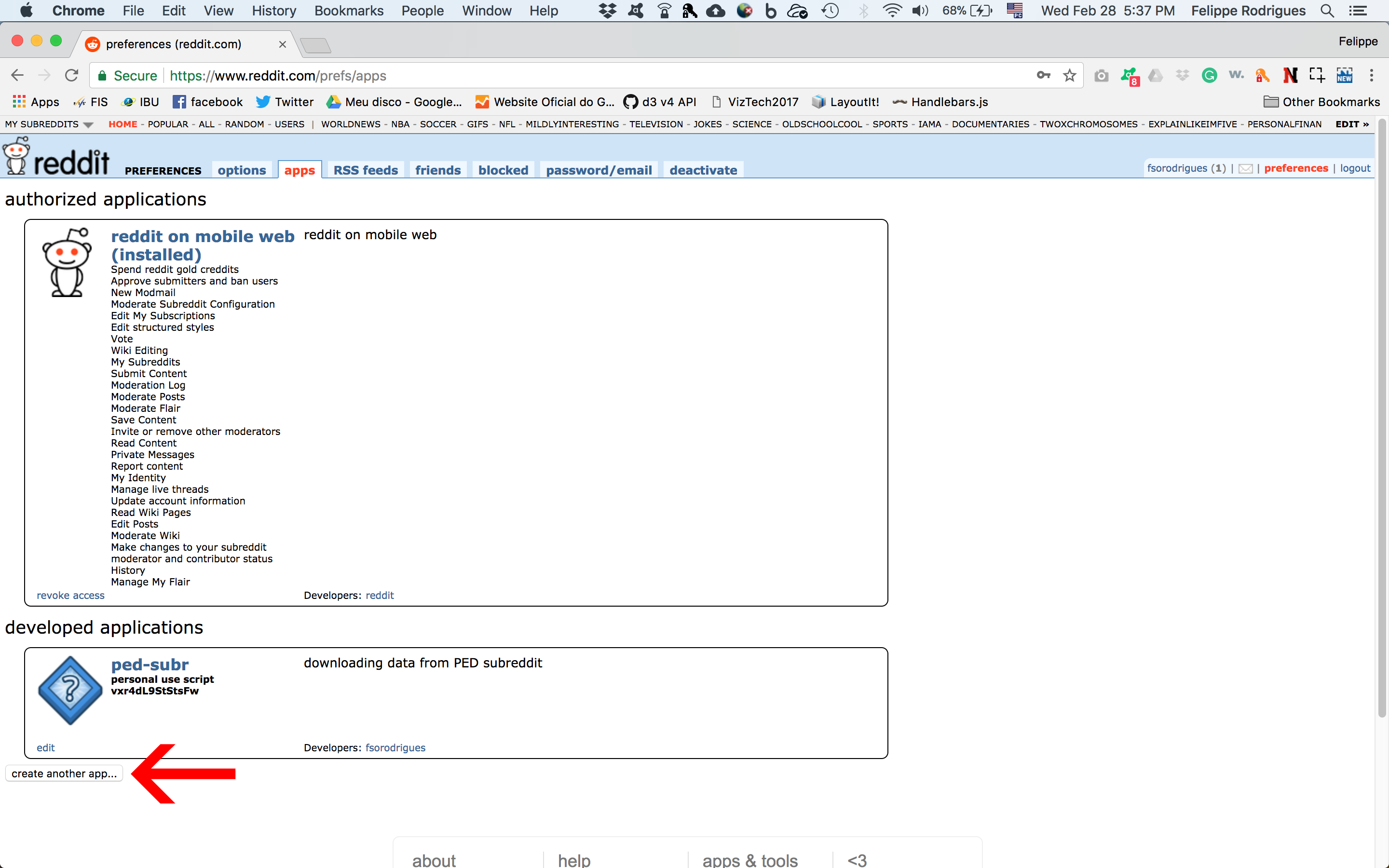
This form will open up.
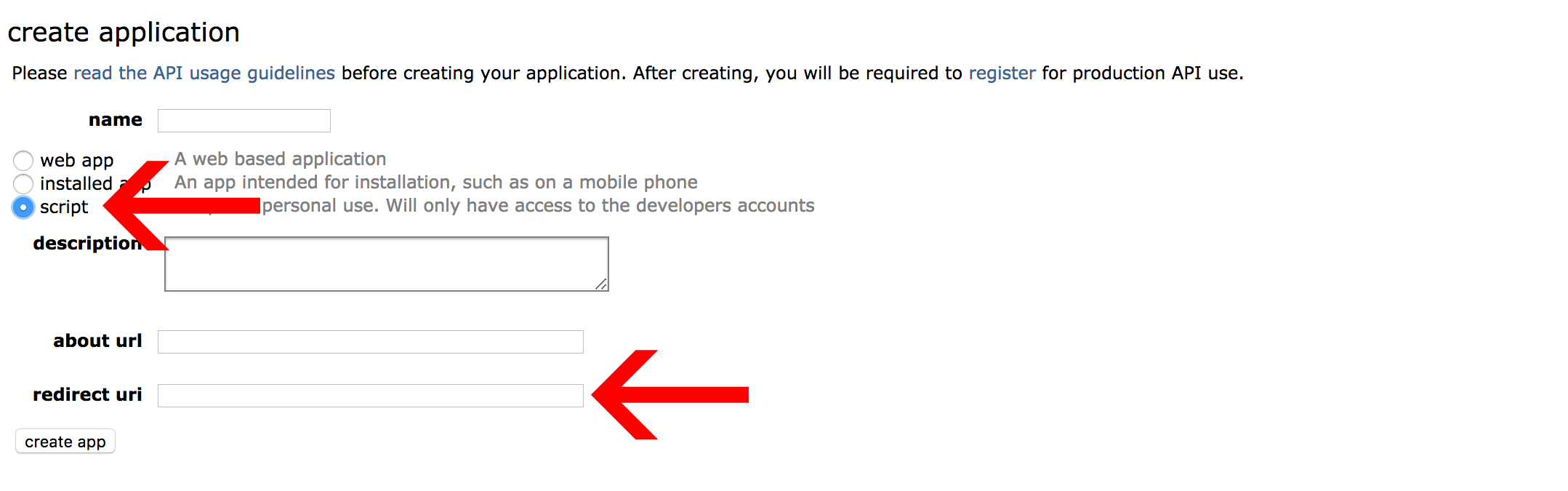
Pick a name for your application and add a description for reference. Also make sure you select the “script” option and don’t forget to put http://localhost:8080 in the redirect uri field. If you have any doubts, refer to Praw documentation.
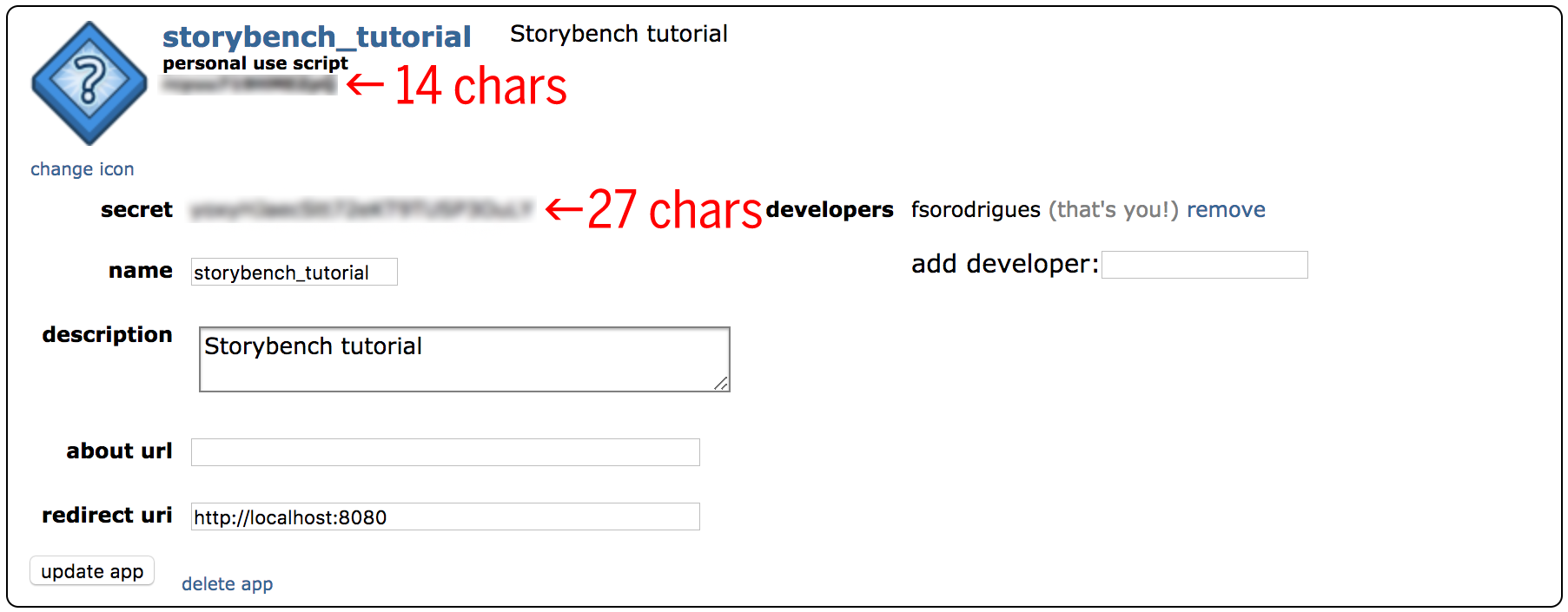
Hit create app and now you are ready to use the OAuth2 authorization to connect to the API and start scraping. Copy and paste your 14-characters personal use script and 27-character secret key somewhere safe. You application should look like this:
The “shebang line” and importing packages and modules
We will be using only one of Python’s built-in modules, datetime, and two third-party modules, Pandas and Praw. The best practice is to put your imports at the top of the script, right after the shebang line, which starts with #!. It should look like:
#! usr/bin/env python3
import praw
import pandas as pd
import datetime as dtThe “shebang line” is what you see on the very first line of the script #! usr/bin/env python3. You only need to worry about this if you are considering running the script from the command line. The shebang line is just some code that helps the computer locate python in the memory. It varies a little bit from Windows to Macs to Linux, so replace the first line accordingly:
On Windows, the shebang line is #! python3.
On Linux, the shebang line is #! /usr/bin/python3.
Getting Reddit and subreddit instances
PRAW stands for Python Reddit API Wrapper, so it makes it very easy for us to access Reddit data. First we connect to Reddit by calling the praw.Reddit function and storing it in a variable. I’m calling mine reddit. You should pass the following arguments to that function:
reddit = praw.Reddit(client_id='PERSONAL_USE_SCRIPT_14_CHARS', \
client_secret='SECRET_KEY_27_CHARS ', \
user_agent='YOUR_APP_NAME', \
username='YOUR_REDDIT_USER_NAME', \
password='YOUR_REDDIT_LOGIN_PASSWORD')From that, we use the same logic to get to the subreddit we want and call the .subreddit instance from reddit and pass it the name of the subreddit we want to access. It can be found after “r/” in the subreddit’s URL. I’m going to use r/Nootropics, one of the subreddits we used in the story.
Also, remember assign that to a new variable like this:
subreddit = reddit.subreddit('Nootropics')Accessing the threads
Each subreddit has five different ways of organizing the topics created by redditors: .hot, .new, .controversial, .top, and .gilded. You can also use .search("SEARCH_KEYWORDS") to get only results matching an engine search.
Let’s just grab the most up-voted topics all-time with:
top_subreddit = subreddit.top()That will return a list-like object with the top-100 submission in r/Nootropics. You can control the size of the sample by passing a limit to .top(), but be aware that Reddit’s request limit* is 1000, like this:
top_subreddit = subreddit.top(limit=500)*PRAW had a fairly easy work-around for this by querying the subreddits by date, but the endpoint that allowed it is soon to be deprecated by Reddit. We will try to update this tutorial as soon as PRAW’s next update is released.
There is also a way of requesting a refresh token for those who are advanced python developers.
Parsing and downloading the data
We are right now really close to getting the data in our hands. Our top_subreddit object has methods to return all kinds of information from each submission. You can check it for yourself with these simple two lines:
for submission in subreddit.top(limit=1):
print(submission.title, submission.id)
For the project, Aleszu and I decided to scrape this information about the topics: title, score, url, id, number of comments, date of creation, body text. This can be done very easily with a for lop just like above, but first we need to create a place to store the data. On Python, that is usually done with a dictionary. Let’s create it with the following code:
topics_dict = { "title":[], \
"score":[], \
"id":[], "url":[], \
"comms_num": [], \
"created": [], \
"body":[]}Now we are ready to start scraping the data from the Reddit API. We will iterate through our top_subreddit object and append the information to our dictionary.
for submission in top_subreddit:
topics_dict["title"].append(submission.title)
topics_dict["score"].append(submission.score)
topics_dict["id"].append(submission.id)
topics_dict["url"].append(submission.url)
topics_dict["comms_num"].append(submission.num_comments)
topics_dict["created"].append(submission.created)
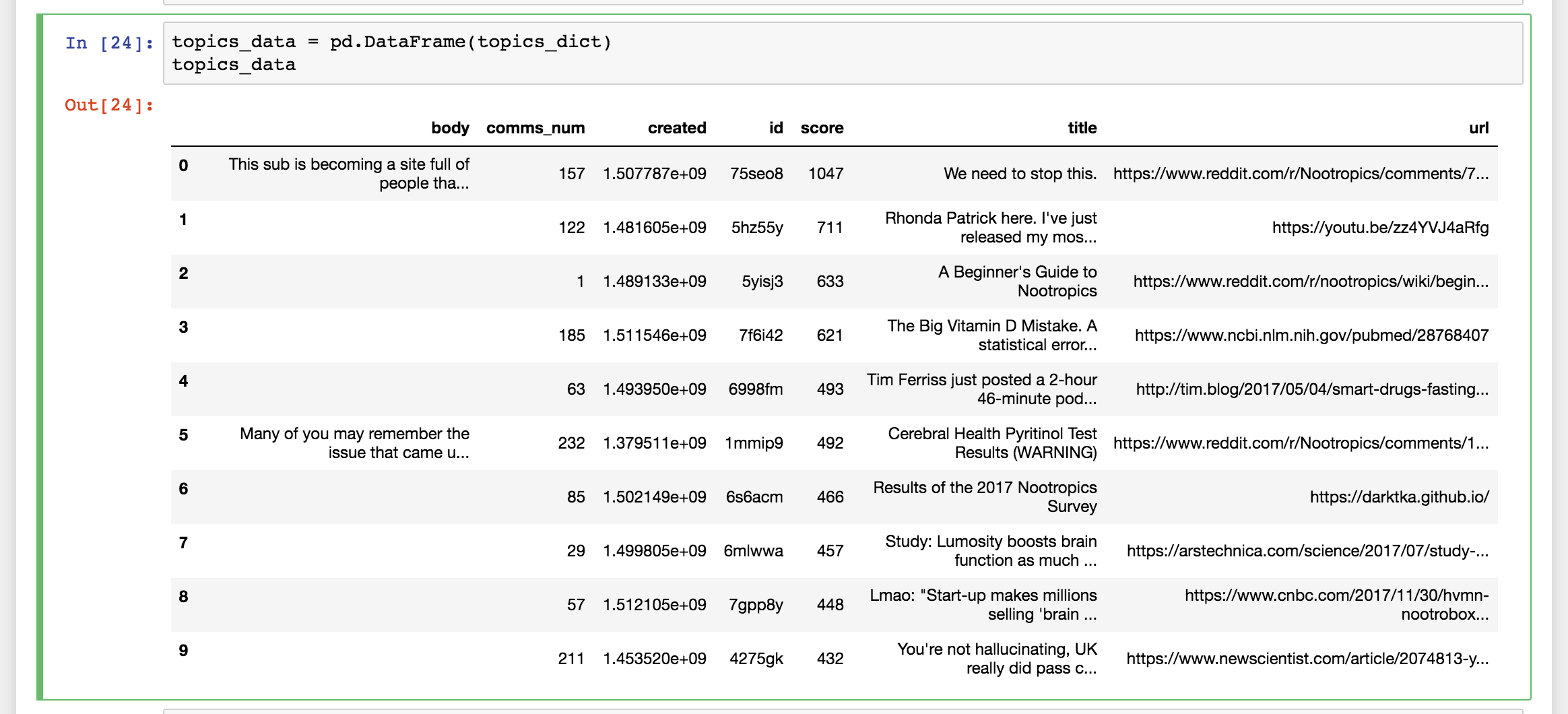
topics_dict["body"].append(submission.selftext)Python dictionaries, however, are not very easy for us humans to read. This is where the Pandas module comes in handy. We’ll finally use it to put the data into something that looks like a spreadsheet — in Pandas, we call those Data Frames.
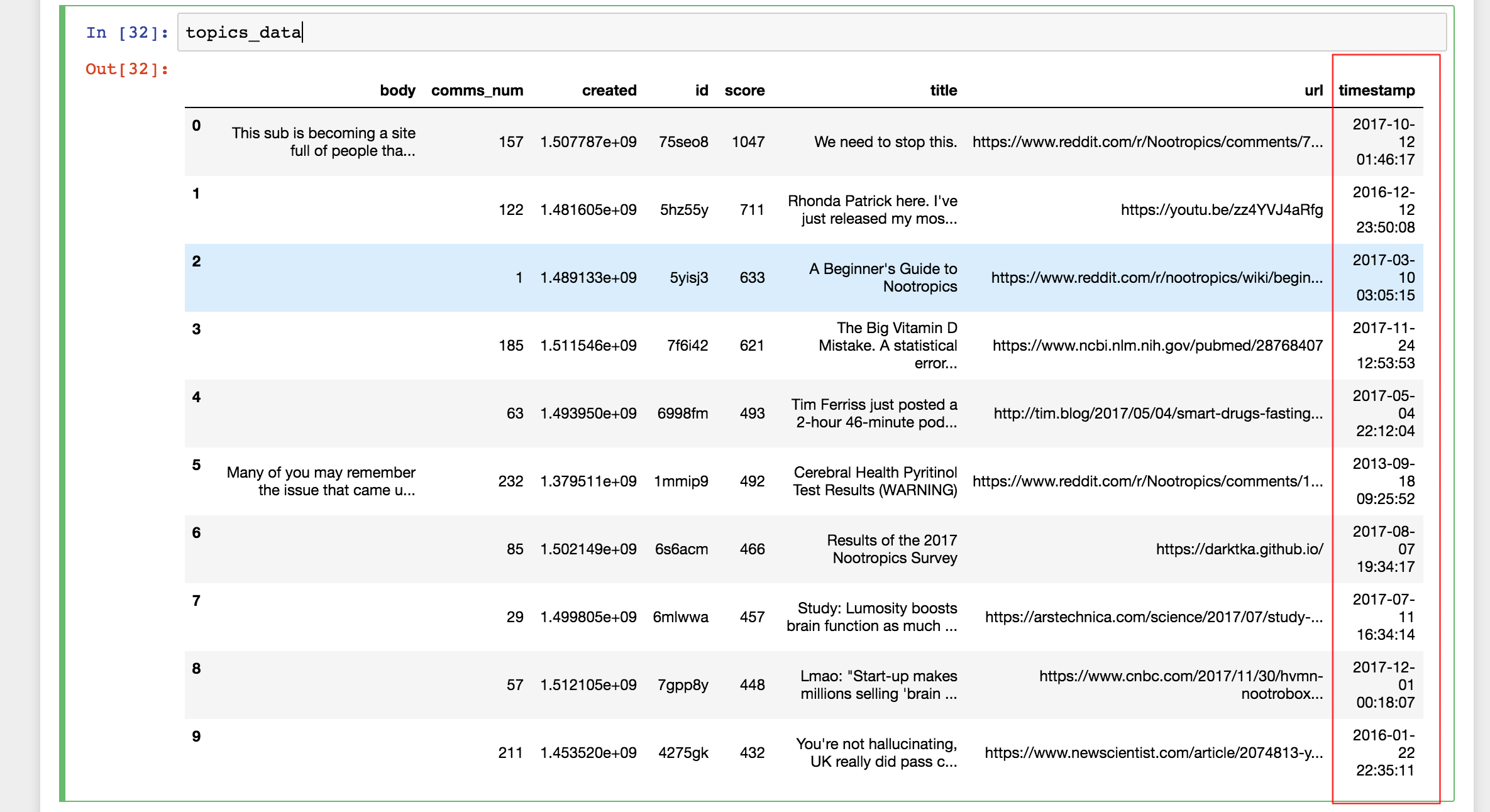
topics_data = pd.DataFrame(topics_dict)The data now looks like this:
Fixing the date column
Reddit uses UNIX timestamps to format date and time. Instead of manually converting all those entries, or using a site like www.unixtimestamp.com, we can easily write up a function in Python to automate that process. We define it, call it, and join the new column to dataset with the following code:
def get_date(created):
return dt.datetime.fromtimestamp(created)_timestamp = topics_data["created"].apply(get_date)topics_data = topics_data.assign(timestamp = _timestamp)The dataset now has a new column that we can understand and is ready to be exported.
Exporting a CSV
Pandas makes it very easy for us to create data files in various formats, including CSVs and Excel workbooks. To finish up the script, add the following to the end.
topics_data.to_csv('FILENAME.csv', index=False) That is it. You scraped a subreddit for the first time. Now, let’s go run that cool data analysis and write that story.
If you have any questions, ideas, thoughts, contributions, you can reach me at @fsorodrigues or fsorodrigues [ at ] gmail [ dot ] com.
- SXSW: ‘Excel is okay’ and other tweet-size insights for data journalists and news nerds - March 17, 2018
- NICAR: Data stories from last year that you could be doing in your newsroom - March 13, 2018
- How to scrape Reddit with Python - March 12, 2018



Thanks for this tutorial, I’m building a project where I need fresh data from Reddit, actually I’m interested in comments in almost real-time. Do you know about the Reddit API limitations? I haven’t started yet querying the data hard but I guess once I start I will hit the limit.
I’ve been doing some research and I only see two options, either create multiple API accounts or using some service like proxycrawl.com and scraping Reddit instead of using their API.
Any recommendation? Thanks
Hey Pompe,
Reddit’s API gives you about one request per second, which seems pretty reasonable for small scale projects — or even for bigger projects if you build the backend to limit the requests and store the data yourself (either cache or build your own DB).
Reddit explicitly prohibits “lying about user agents”, which I’d figure could be a problem with services like proxycrawl, so use it at your own risk.
I’ve experienced recently with rate limiter to comply with APIs limitations, maybe that will be helpful.
Send us the url for that project!
Best,
Felippe
I would recommend using Reddit’s subreddit RSS feed. reddit.com/r/{subreddit}.rss
Thanks for this tutorial, I just wanted to ask how do I scrape historical data( like comments ) from a subreddit between specific dates back in time? For example, I want to collect every day’s top article’s comments from 2017 to 2018, is it possible to do this using praw? If I can’t use PRAW what can I use? Thanks so much!
Hey Jay,
This link might be of use.
https://github.com/aleszu/reddit-sentiment-analysis/blob/master/r_subreddit.py
It is, somewhat, the same script from the tutorial above with a few differences.
If you scroll down, you will see where I prepare to extract comments around line 200. It relies on the ids of topics extracted first. If I’m not mistaken, this will only extract first level comments. More on that topic can be seen here: https://praw.readthedocs.io/en/latest/tutorials/comments.html
It is not complicated, it is just a little more painful because of the whole chaining of loops.
Anyways, let us know how it turns out.
Is there a sentiment analysis tutorial using python instead of R? Any recommendations would be great. Thanks.
Hey Muhammad,
Check out this by an IBM developer.
I’ve never tried sentiment analysis with python (yet), but it doesn’t seem too complicated.
It requires a little bit of understanding of machine learning techniques, but if you have some experience it is not hard.
Send us a note with what you create.
Best,
Felippe
Hey Felipe,
Thanks for this tutorial. I am completely new to this python world (I know very little about coding) and it helped me a lot to scrape data to the subreddit level. One question tho: for my thesis, I need to scrape the comments of each topic and then run Sentiment Analysis (not using Python for this) on each comment. How would I do this? is there any script that you already sort of have that I can match it with this tutorial?
I feel that I would just need to make some minor tweaks to this script, but maybe I am completely wrong.
Thanks!
Thanks for the awesome tutorial! How do we find the list of topics we are able to pull from a post (other than title, score, id, url, etc. that you list above)? I checked the API documentation, but I did not find a list and description of these topics. Some posts seem to have tags or sub-headers to the titles that appear interesting. Thanks again!
Hi,
Thanks for this. I got most of it but having trouble exporting to CSV and keep on getting this error
—————————————————————————
TypeError Traceback (most recent call last)
in ()
—-> 1 topics_data.to_csv(‘FILENAME.csv’,Index=False)
TypeError: to_csv() got an unexpected keyword argument ‘Index’
—————————————————————————
What am I doing wrong? Sorry for the noob question.
to_csv() uses the parameter “index” (lowercase) instead of “Index”
Awesome tutorial.
Do you know of a way to monitor site traffic with Python?
Thanks.
Hello,
Is there a way to pull data from a specific thread/post within a subreddit, rather than just the top one? Assuming you know the name of the post.
Thanks!
Hey Robin
Sorry for being months late to a response.
If you look at this url for this specific post:
https://www.reddit.com/r/redditdev/comments/2yekdx/how_do_i_get_an_oauth2_refresh_token_for_a_python/
‘2yekdx’ is the unique ID for that submission.
You can use it with
reddit.submission(id='2yekdx')That will give you an object corresponding with that submission. You can then use other methods like
submission.some_method()to extract data for that submission.
Hi,
thanks for the great tutorial!
I coded a script which scrapes all submissions and comments with PRAW from reddit for a specific subreddit, because I want to do a sentiment analysis of the data. That’s working very well, but it’s limited to just 1000 submissions like you said.
Do you have a solution or an idea how I could scrape all submission data for a subreddit with > 1000 submissions?
I don’t want to use BigQuery or pushshift.io or something like this. I only want to code it in python.
I would really appreciate if you could help me!
Thanks!
Hi Daniel,
Can you provide your code on how you adjusted it to include all the comments and submissions?
Daniel may you share the code that takes all comments from submissions?
Anyone got to scrape more than 1000 headlines
Hi!
Thanks a lot for taking the time to write this up! I had a question though: Would it be possible to scrape (and download) the top X submissions? (So for example, download the 50 highest voted pictures/gifs/videos from /r/funny) and give the filename the name of the topic/thread?
Hey Nick,
top_subreddit = subreddit.top(limit=500)Something like this should give you IDs for the top 500.
From there you can use
submission = reddit.submission(id='39zje0')
submission.some_method
....
Check this out for some more reference.
https://praw.readthedocs.io/en/latest/getting_started/quick_start.html#determine-available-attributes-of-an-object
Thanks, this was very helpful.
This tutorial was amazing, how do you adjust to pull all the threads and not just the top? Thank you!
Is there any way to scrape data from a specific redditor?
Hi, Shawn,
You can explore this idea using the
Reddittorclass ofpraw.Reddit.Here’s the documentation: https://praw.readthedocs.io/en/latest/code_overview/models/redditor.html#praw.models.Redditor
I have never gone that direction but would be glad to help out further.
Let us know how it goes.
Hey Felippe,
With this:
iteration = 1
for topic in topics_data[“id”]:
print(str(iteration))
iteration += 1
submission = abbey_reddit.submission(id=topic)
for top_level_comment in submission.comments:
comms_dict[“topic”].append(topic)
comms_dict[“body”].append(top_level_comment.body)
comms_dict[“comm_id”].append(top_level_comment)
comms_dict[“created”].append(top_level_comment.created)
print(“done”)
I got error saying ‘AttributeError: ‘float’ object has no attribute ‘submission’
Pls, what do you think is the problem? Thanks
Appreciate this tutorial! Anyway to scrape the usernames of the poster as well?
Thanks again
Thank you. This was a fantastic tutorial. However, after running for a few times, the api no longer works. Why is that?
Hi Felippe,
Amazing work really, I followed each step and arrived safely to the end, I just have one question. Is there a way to do the same process that you did but instead of searching for subreddits title and body, I want to search for a specific keyword in all the subreddits.
For instance, I want any one in Reddit that has ever talked about the ‘Real Estate’ topic either posts or comments to be available to me.
If you did or you know someone who did something like that please let me now.
Thanks a lot:)
Hi Felippe!
Thanks for this, it’s very helpful. The question I have is, what if I wanted to scrape only the posts with a specific flair?
simply adding topics_dict[“link_flair_text”].append(submission.link_flair_text) doesn’t work.
Thank you for sharing this article. I was looking for how to scrap Reddit for a story, and apparently, they even have an API.
Cheers for sharing how to do it.
Thank you so much for sharing this. I’m new to Python, but this worked well for me!
Thank you so much for the script!
I would like to modify the code as I need only those threads to be saved which have a minimum length of lets say -100
is it possible to modify the request using something like this?
for submission in top_subreddit:
if len(submission.selftext <- 100
continue
else: pass
Easy to follow instructions, extremely hepfull for a novice like me. Thank you so much 😀
I think there is a typo at
topics_data = pd.DataFrame(topics_dict)
I think it should be topics_dict because that works for me haha