To scrape or not to scrape: technical and ethical challenges of collecting data off the web
Sophie Chou is a graduate student at the MIT Media Lab focusing on machine learning and journalism. She attended a session on web scraping at the 2016 NICAR conference.
The Internet is a smorgasbord of information and, with some basic coding skills in a programming language like Python, it can be tempting to collect everything interesting that you see.
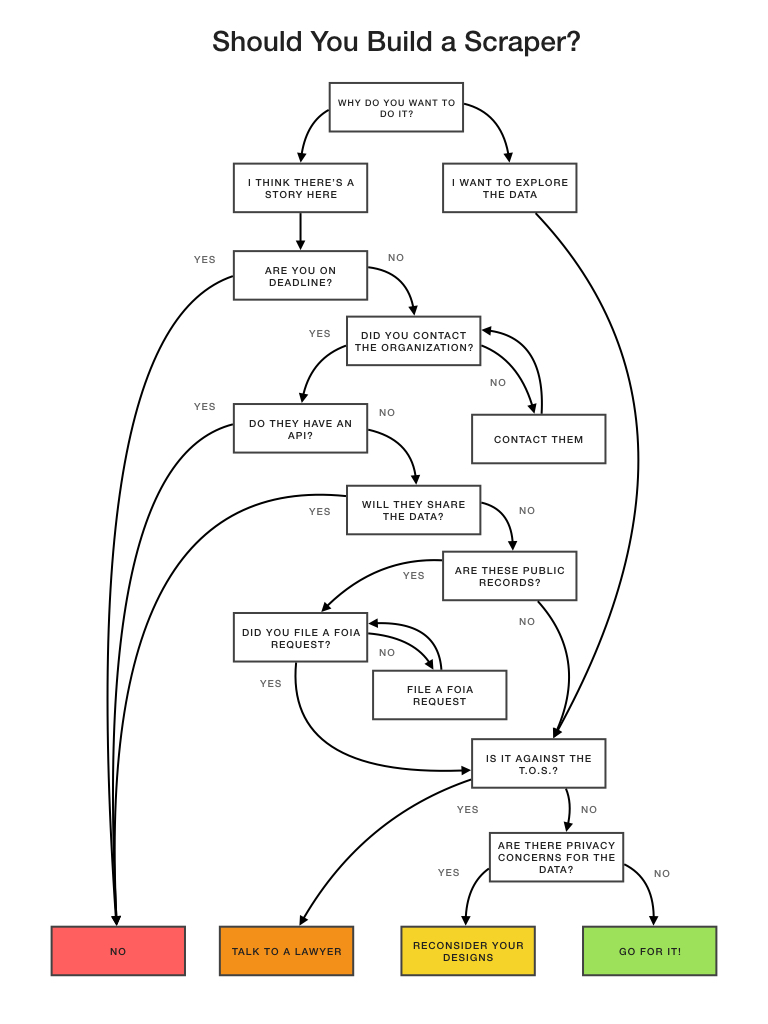
But just because you can scrape it does that mean you should? As a data journalist, when is web scraping the right choice? And, more importantly, when is it right for you?
“Consider data scraping like window shopping. Look, photograph, but do not modify or take the object,” said Ricardo Brom, a data journalist at Argentine newspaper La Nacion. Brom, along with David Eads of NPR, Amanda Hickman of Buzzfeed, and Martin Burch of the Wall Street Journal, presented a panel on the subject at NICAR16, IRE’s recent Computer Assisted Reporting conference in Denver, Colorado. Below are some guidelines synthesized from the session, which was titled “Best Practices for Scraping: From Ethics to Techniques.”
What is it good for?
Scraping is best for finding story ideas and getting a sense of aggregate data, provided you correctly interpret the data you are collecting. However, the most important outcomes and stories often arise from the process rather than the data itself.
“It can open up conversation,” said Eads. While teaching at Free Geek Chicago, he ran a longterm project to scrape the Cook County jail inmate locator. Although Cook County refused to release the data to the public, scraping the data and making it available through a website put pressure on them to do so.
What should you ask others beforehand?
Before you begin, it’s always a good idea to contact the organization that’s hosting the data online. Often, there might be an easier and more accurate way to access the data—whether through an API or a direct download of the database. Even if you walk away empty handed, it’s imperative to communicate to ensure that the data you’re collecting is both up-to-date and correctly interpreted.
Pushback can also be an indicator of flaws or sensitivities in the data. “There’s so much incorrect data and old data that should have been deleted but never was,” said Eads. “[That] made them nervous about releasing bulk data.” Hickman, who worked on a scraping project to track the court system in Philadelphia, found that often times protecting the privacy of the data source was a large factor in hesitation to release datasets. “One of the questions to ask [is] if they’re worried about privacy concerns, what are you doing with it?”
What should you ask a lawyer beforehand?
Regardless of the form and intent of the final product, if the Terms of Service (T.O.S.) of the site you are planning to scrape expressly forbids it, make sure to talk to a media lawyer. The same goes for robots.txt files. Even though they are not necessarily legally binding, they could be potentially used against you in a legal case.
Another important factor to consider is whether or not the material you’re scraping is copyrighted, which can present additional challenges. “Talk to a lawyer and understand your fair use rights,” said Hickman.
What should you ask yourself beforehand?
Beyond the ethical concerns outlined above, it’s also a good idea to sketch out technical considerations before scraping. What assumptions are you making about the underlying data model? Furthermore, do you have the means to take care of the data?
Depending on the size and longevity of the project, server bills can quickly rack up. If the goal of the project is to collect longitudinal data, it’s a good idea to estimate how long it would take for the scraper to break (and thus require maintenance) by tracking past changes on the Internet Archive.
How you decide to design the final product is also an important factor. Through which medium will you tell the story? Creating a web app that makes the data searchable can lead to very different privacy concerns than a static, one-off visualization. Eads also recommends keeping in mind the mosaic effect, where your data might be contributing to existing public data in unveiling confidential information about individuals, especially within vulnerable populations.
What should you make sure to include in your code?
If you do decide to start a scraping project, add some additional checks to your basic code. Make sure to include scripts for quality assurance and data validation. While working with the court records, Hickman came up with ways to programmatically confirm that dates being collected were valid, money was in dollar amounts, and that addressed being listed were in fact in Philadelphia. She was then able to catch and confirm outliers in the dataset. In these cases, prior knowledge of the data and talking to its creators can be helpful guidelines.
Furthermore, ensure that your script treads lightly. Scraping the Cook County jail inmate tracker actually caused Eads to bring the site down, by overloading the web server. This led to unforeseen ethical implications, preventing family and friends of inmates from temporarily accessing contact information.
To prevent similar consequences, cache your results as you scrape them to avoid excessive visits to sites. Detect changes to web pages from HTTP headers, and make sure to put your script on temporary timeout between requests.
Scraping as a learning tool
Although scraping presents many technical and ethical challenges, it remains a valuable tool to many data journalists. A large part of its popularity lies in the fact that scraping projects are a great introductory coding project. Although Eads does not consider his scraping project a success in terms of producing stories, he found it to be an engaging way to teach data journalism at Free Geek, something that he had struggled with. “The data itself became a secondary part of the project to all the community organizing, the learning,” he said.
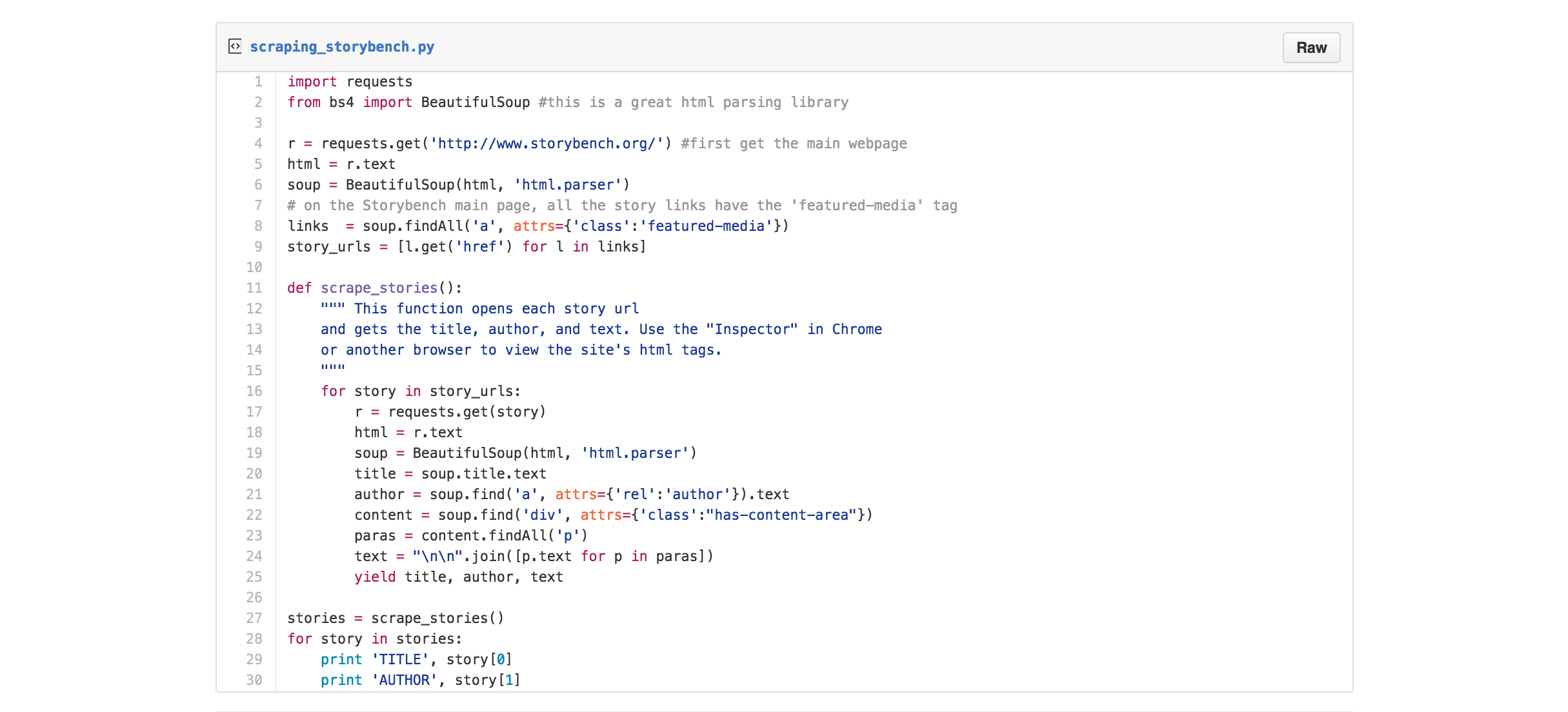
Ready to learn some scraping skills? Try out the example code below to scrape Storybench.org!


