How to use Tabula to extract tables from PDFs
Tabula is a tool for extracting tabular data from PDFs built by Manuel Aristarán, Jeremy Merrill and Mike Tigas. The following is a simple tutorial for using Tabula.
Download Tabula
To start using Tabula, download it here.
Extract Tabula and run a local server
Extract Tabula and open the program. Then navigate to localhost:8000 in your browser. You should get this:
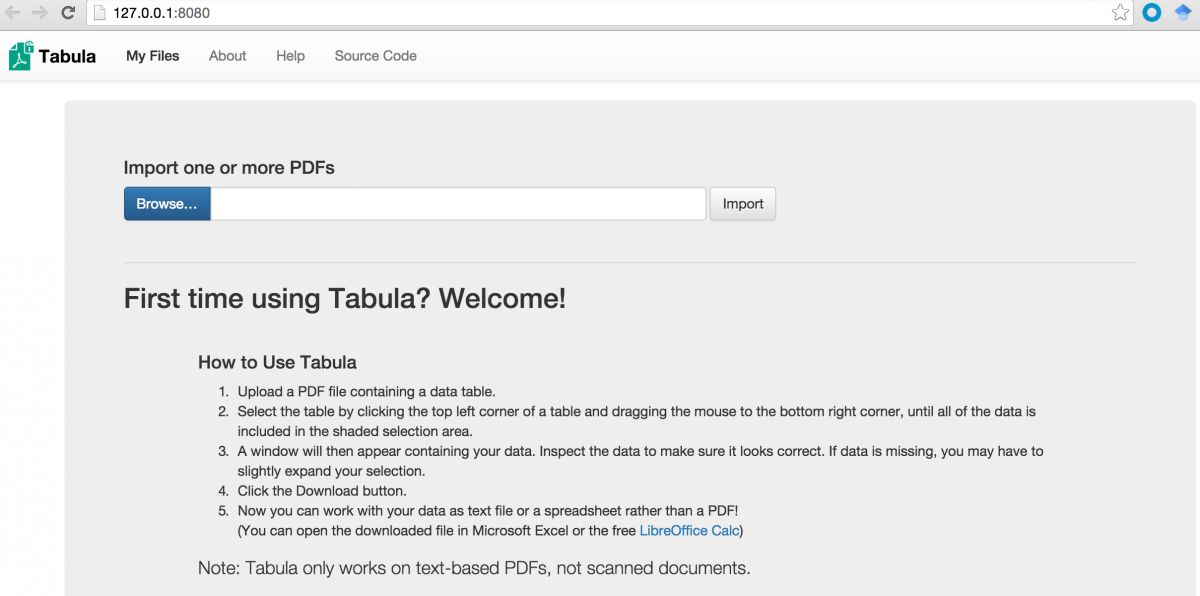
Upload a PDF
Click the Browse button and upload a PDF that has tables you want to extract. Then click Import.
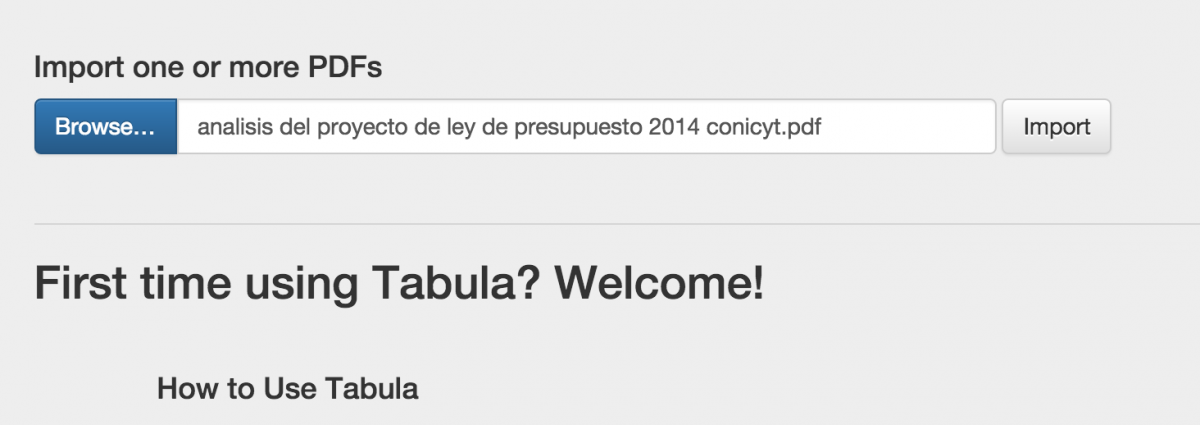
*For Tabula to read your PDFs, they must have embedded text. Image-based PDFs cannot be read by Tabula and will result in the error message “Sorry, your PDF file is image-based.”
Highlight the tables
Click Autodetect Tables and Tabula will try to find the tabular data inside the PDF you’ve uploaded. If it does not highlight the table you want to extract, simply highlight them yourself as if you were taking a screenshot. You can always X out of your selection and retry. Be sure to highlight the complete table including borders.
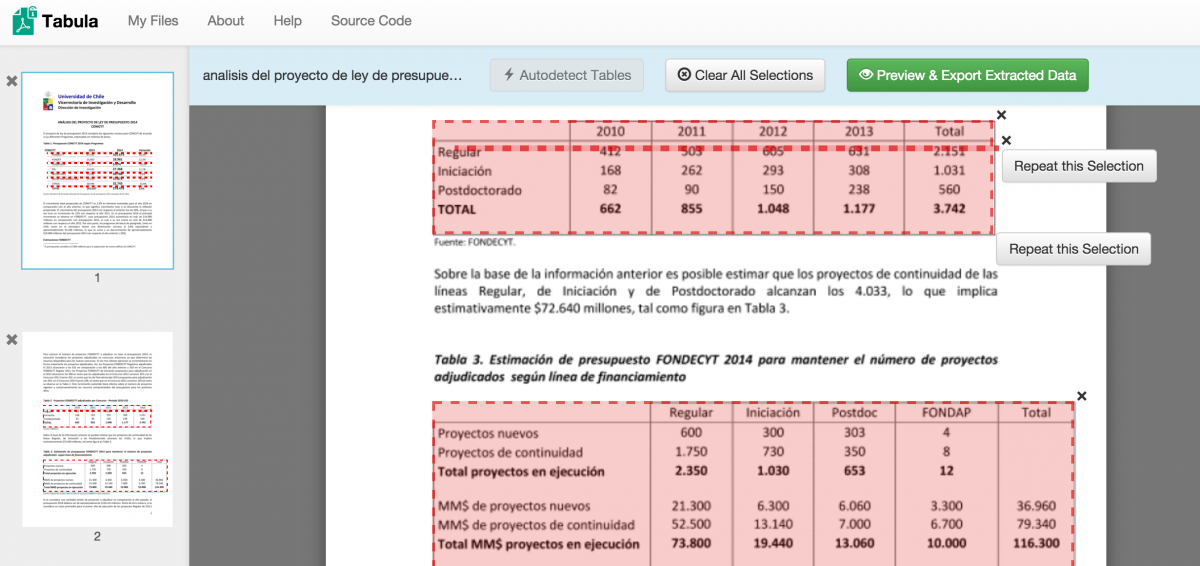
Export your data
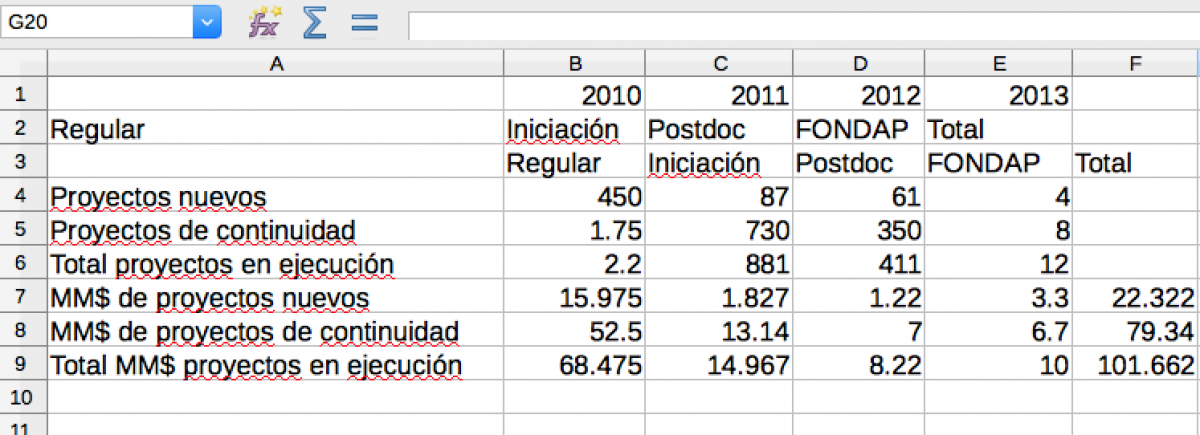
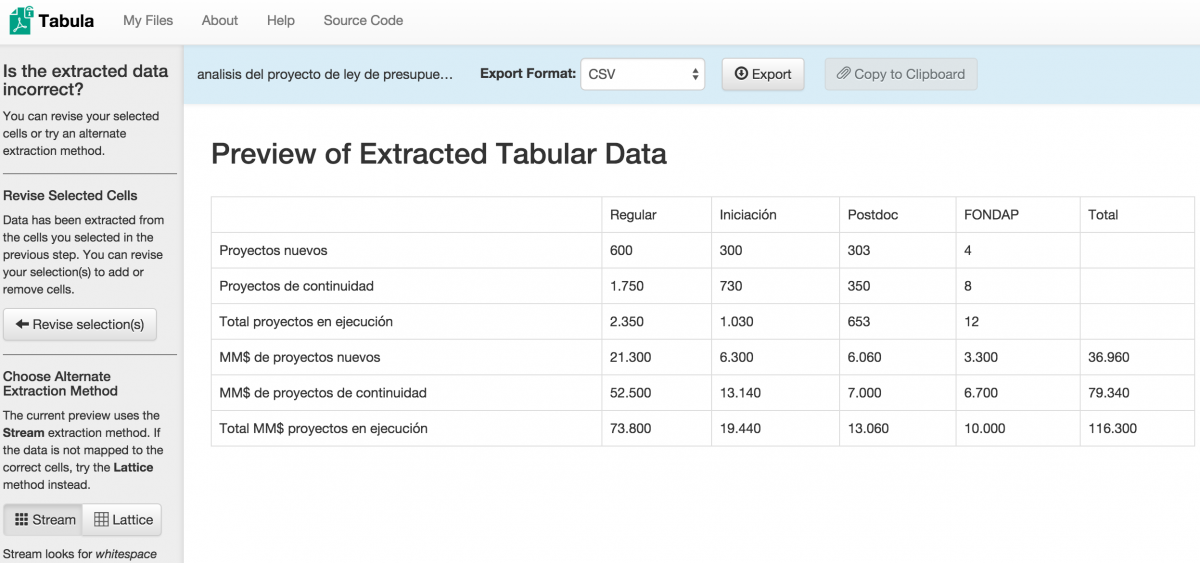
After you’ve highlighted the table you want to extract, click Preview & Export Extracted Data. You’ll be brought to this screen. Notice that Tabula has extracted several separate rows: one row containing 2010, 2011, 2012, 2013 in four columns; one with Regular, Iniciación, Postdoc, FONDAP, and Total in five columns; and one full table. Extracting the data incorrectly is common. Simply click Revise selection(s) on the left menu to go back and retry.
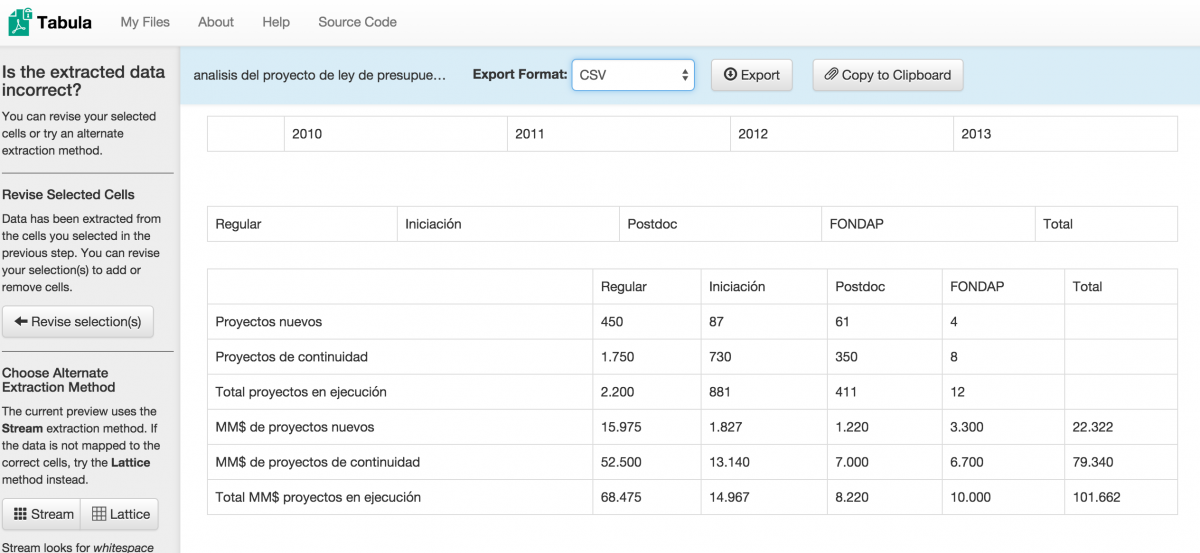
We were very careful the next time around to highlight the table correctly.
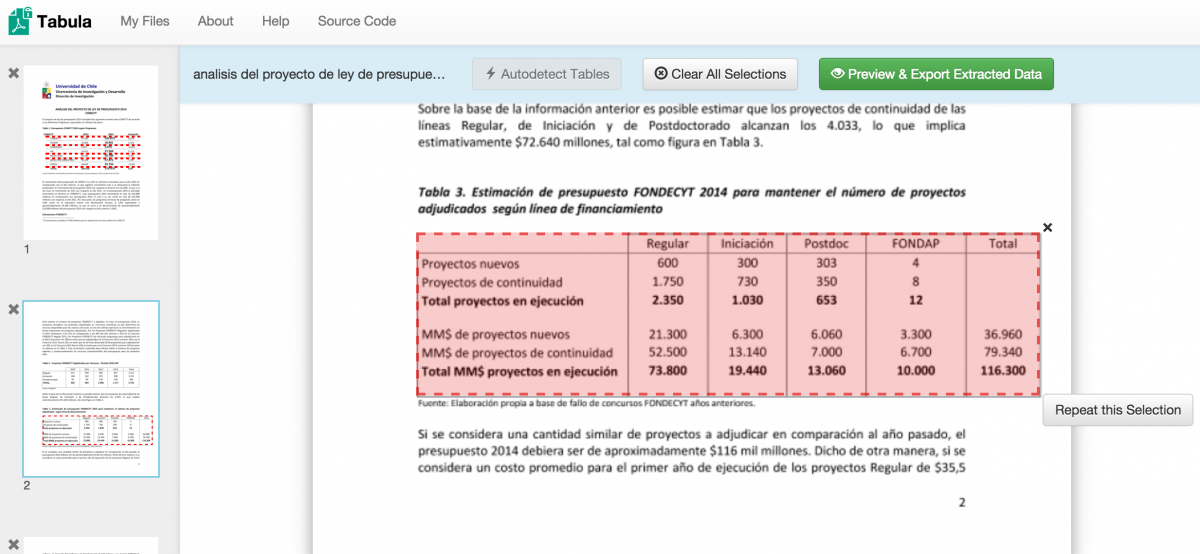
Clicking Preview & Export Extracted Data then gave me the data I was looking for, correctly formatted.
Double-check your data by cross-referencing your table
Double-check your Tabula preview of your table with the original PDF. We use another program, like Preview or Adobe Acrobat, to compare. This way, you’ll make sure no data has been lost or misread.
Export your table as a spreadsheet
Once you’ve double-checked your data, Tabula can export your table in a variety of formats.
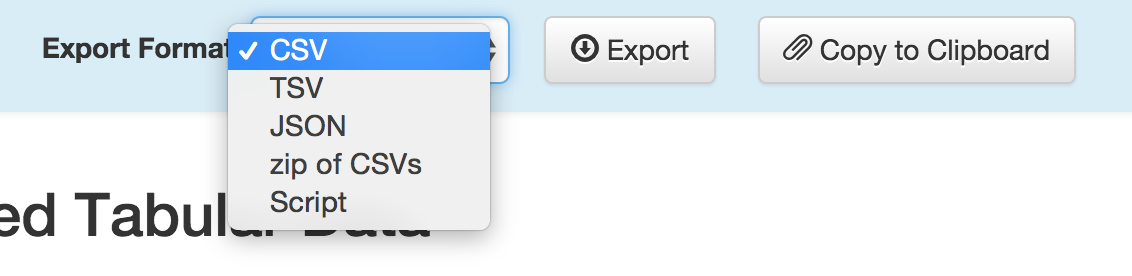
We exported our table as a CSV and were then able to open it in any spreadsheet program to continue manipulating. Thanks, Tabula!