
Mapping disinformation and igniting insight with Media Cloud’s Emily Boardman Ndulue
Editor’s note: Danica Jefferies is a graduate assistant for the Co-Lab for Data Impact and works with Emily Ndulue.
Emily Boardman Ndulue recently arrived at Northeastern University, but she has been conducting research for several years, including working alongside interdisciplinary analysts at the MIT Media Lab. In 2018, she joined the Media Cloud project, featuring an open-source repository for media analysis that houses a monumental 1.5 billion news stories from over 60,000 sources globally.
On Thursday, she talked with students and shared a range of applications from her projects at “Pizza, Press & Politics,” a weekly speaker series hosted by the Northeastern School of Journalism.
Ndulue said her work “lives in this interesting hybrid space” of an academic research group, as to not bias results, but with a pro-social mission. As a result, Media Cloud focuses on helping journalists, activists, as well as non-profits and foundations understand and curate content based on metadata and their insights. Recently, her team has been further exploring the role of news in the dissemination of false information.
“Are people co-opting factual news and misconstruing it on social media? Or [are] there particular news sources that are really contributing to the origination and spread of misinformation?” she asked.
Some of the news disinformation campaigns she has worked on range from topics such as “Greta Thunberg is an Antifa operative” to circulating links to mass shooter manifestos. While open-source, there are still private collections within Media Cloud to diminish the harm that could be done by sharing precise web addresses to content capable of inspiring similar events.
As the threat of disinformation looms large today, Ndulue explained how the current state of social media exacerbates and allows for trustworthy sources to also be taken advantage of. This includes preprint archives, tools for scientists to post early results of research online and biomedical professionals to build off others’ work.
“Actual scientists when using them understand the limitations, but because they’re open online, lots of people can see them and then go misconstrue the results,” said Ndulue. “There’s certainly a lot of that happening with COVID coverage and so we’re able to see where are links to these pre-prints showing up on the web, in news and in social? And how are they being talked about?”
There are three main Media Cloud tools for users to interact with media collections across the world. Ndulue demonstrated the Explorer tool, which in conjunction with Topic Mapper and Source Manager, provides researchers with multifaceted insights on a diverse assortment of news corpuses.
By categorizing articles with theme tags established by The New York Times, the collections and widgets are “babysat” by no other than a real person. “It’s always critical that the [researcher’s] eye come in and read and re-evaluate. And take that as an arrow towards a direction to dig, and see if there’s something else there and see if it holds up,” said Ndulue.
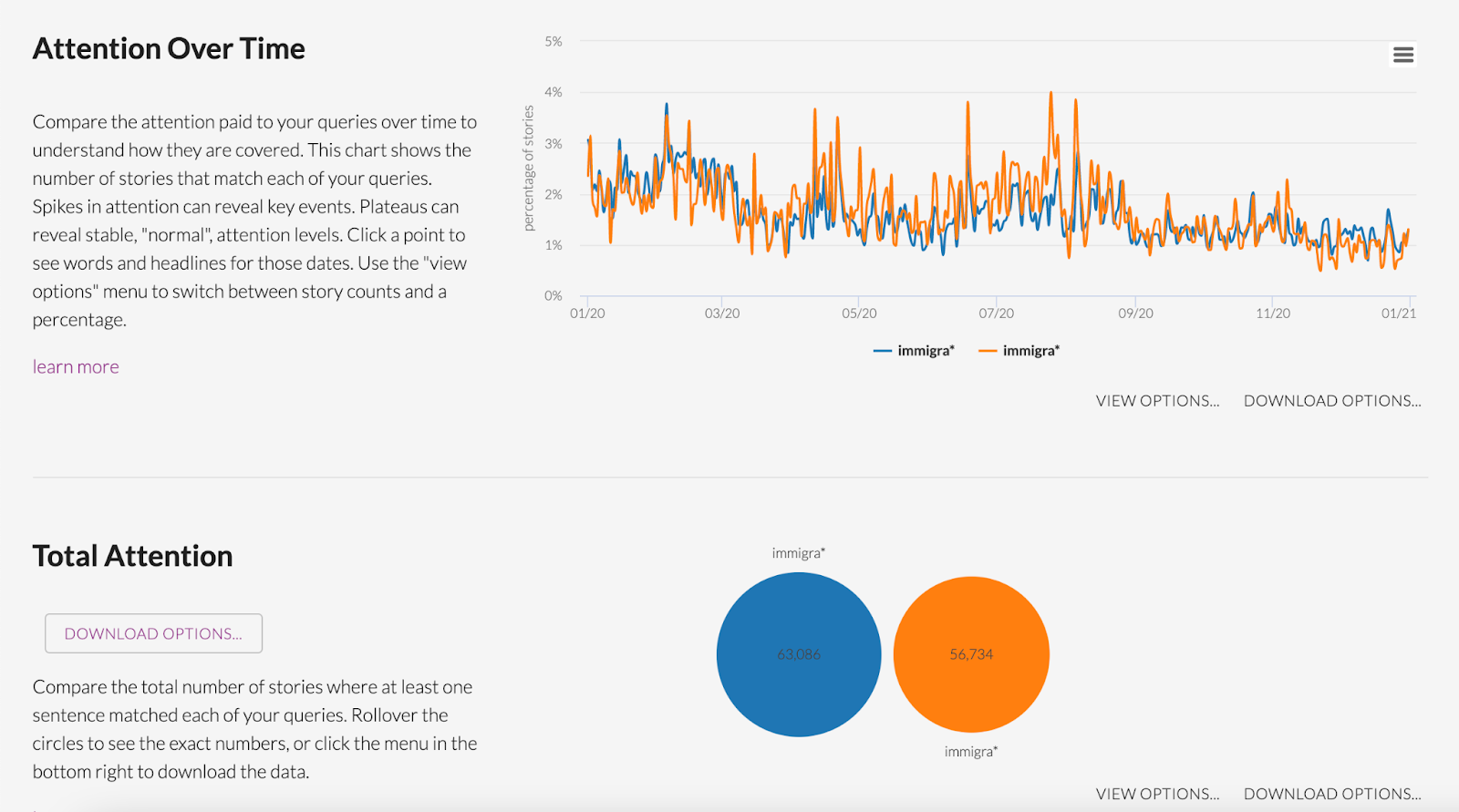
One of the most important metrics for comparing coverage in the news is the normalized percentage, which Media Cloud’s tools are programmed to prioritize over raw story count.
“That’s something that’s really powerful about our tool, if we’re ingesting close to everything that these publications produce,” said Ndulue.

“Also, not just the volume, but when peaks and coverage happen. We plot the hits to a certain topic over time and we’re able to see large increases around a certain date or event. Or maybe one that you would expect to see that isn’t there, something that you thought was newsworthy, that isn’t causing a spike in attention.”
Another benefit to the platform’s extensive access — users can download a CSV containing data about the stories in any given query, which frequently includes the URL, publisher, date and detected theme tags. While Media Cloud can’t access full text, the content is run through an RSS feed, bypassing paywalls.
Ndulue, an expert of the boolean search query, emphasized the importance of knowing how to use distinct and crafty combinations of ANDs, ORs, quotation marks and asterisks in order to retrieve accurate records from the database. Media Cloud’s infrastructure, in combination with her expertise, prevail as innovative methods for understanding and implementing data-informed strategy on behalf of users on all sides of the media ecosystem.
- Nadieh Bremer on thinking outside the (x,y) axes - February 11, 2022
- Mapping disinformation and igniting insight with Media Cloud’s Emily Boardman Ndulue - February 4, 2022
- How FiveThirtyEight’s Julia Wolfe addresses data literacy - October 27, 2021


