
How one digital humanist visualized the shapes of 50,000 novels
This September, the University of Miami will host the first ever symposium exploring the intersection between data journalism and the digital humanities. The conference is premised on the idea that the two fields can learn from each other, as they face shared challenges and opportunities in areas like textual analysis and data visualization.
One of the initiatives in the digital humanities that has received mainstream press coverage are experiments calculating story shapes. You may have read one last month in The Atlantic about a team of researchers at the University of Vermont’s Computational Story Lab that found that the plots of novels take on one of six basic trajectories.
Matthew Jockers, an associate professor of English at the University of Nebraska-Lincoln, published his own findings on story shapes about a year and a half ago — along with the algorithm he developed to analyze a corpus of over 50,000 novels.

Written in R, a programming language used on data journalism desks for statistical analysis, the Syuzhet package uses sentiment analysis to detect the shapes of plots. Jockers’ findings were largely confirmed by the team at UVM and support the theory set out by Kurt Vonnegut over forty years ago that there are only a few basic plot shapes that appear in fiction.
Jockers designed Syuzhet for the analysis of long-form narratives, but he says he’s received reports of individuals using it for myriad purposes. As long as the output is tested against human-coded data, Syuzhet should work across genres and story lengths, according to Jockers. Could the more tech-savvy journalist use Syuzhet to experiment with plotting the emotional trajectories of speeches, memoirs, or even the latest bestseller list?
We spoke with Jockers about the challenges of sentiment analysis, Syuzhet and big names to watch in the areas of text mining and natural language processing.
In terms of how digital humanities is being received and understood within the “straight humanities,” have you found there’s skepticism especially around work in sentiment analysis?
As academics we’re supposed to be skeptical. I think healthy skepticism is good. I think there’s also a thread of unhealthy knee-jerk skepticism, and so there’s both. Something like sentiment analysis — yeah, there are problems. Dictionary-based methods, for example, just look to see if certain words are in a sentence. They say, “Are there words that our dictionary says are happy words and are there words in the sentence that our dictionary says are negative words?”
Well, what happens when a sentence says “He was not handsome?” “Handsome” is a positive word but the addition of “not” negates that, so it’s actually a negative sentiment, not a positive one. So should people be skeptical of dictionary methods? Sure. And they should be skeptical to the point of asking the next question, which is “how well does that tool do compared to human-coded data?” So you need to validate the dictionary results against human-coded data.
Right. And you did that with your students, right?
Yes, and they’re doing it again now because last year we developed a new dictionary in my lab, and I’ve now now got a team of six students who have been validating it all summer.
So, the question being asked is, “how well does that machine result reflect what I actually think when I read the book?” The answer is about 80%. About 20% of the time, the machine is showing a result that is different from what the humans think. But when we look at what human beings think we find that they only agree with each other about 80% of the time.
It seems like a lot of people are trying to answer this question about story shapes as well. I’ve seen people replicating the work you’ve done and coming up with their own models. If you’re a journalist and you want to try to use this in a creative way, how do you go about confirming and evaluating what’s inside the different algorithms?
This is coincidence or irony or something, but I just got off the phone with Andy Reagan, who’s the researcher at the University of Vermont who…
Right, yeah!
Yes. We finally talked today, and I shared some data with him and we went back and forth kind of critiquing each others’ approach. What he’s done is very very similar to what I’ve done. The differences in fact are more like fine points rather than big differences. So I’m delighted. He faced the same challenges and came up with his own solution which looks very much like my solution, except for the fine points. The shapes my tool is detecting look like the shapes his tool is detecting, and I think that’s great. It’s validation through a different method.
How do you decide what the best method out there is? Well, as far as I know, Andy hasn’t done any of the human validation that I’ve been doing. So, I suppose you could say that my method’s been a bit more vetted, but what Andy’s doing looks good. He’s a mathematician, he has some training that I don’t have, so it’s interesting to see how two perspectives converge. One of the problems he has is that his collection of books isn’t really a collection of narratives. He pulled 1700 items from Project Gutenberg but they include short story collections, they include works of nonfiction, histories, philosophy books, whereas the corpora I’ve been working with are all novels. They’re linear narratives. Andy indicated that this is something he is correcting in his corpus.
Speaking of linear narratives and Syuzhet, if someone wanted to use Syuzhet to look at presidential speeches, for example, is that an error? If people want to use this, as long as the genre is consistent, will it still work if the corpus isn’t fiction?
I have been blown away by the ways that people have taken this package and used it for things that I never imagined. I had one guy, and I can’t remember where he’s from, but he’s a psychologist or a psychiatrist and he was using the tool to analyze his own notes about his patients in order to see if he could track an increase in his own positive language to see if the patient was improving over time.
That is crazy. Did he find it worked?
Well, yeah, as far as I know. He wrote a very positive email, and this was his application of it. Of course it gave me pause, because the stakes are obviously a little higher when we’re talking about a person’s mental health. But I’ve heard from lots of people who applied it to all kinds of things, and again I guess it’s all about if they validate it. If they have human-coded data and the machine is reflecting what we would think intuitively, subjectively, then great, go for it.
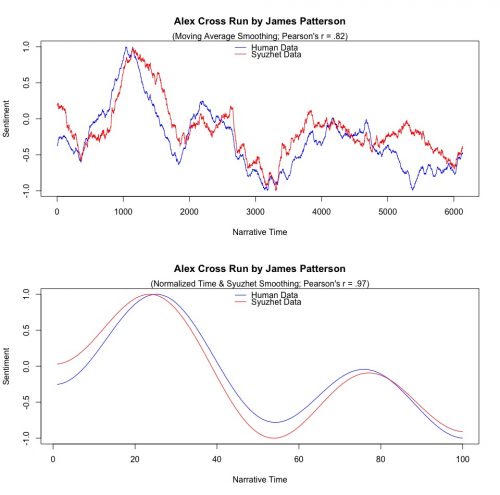
Of course, there are controversial things about how you go about this validation, so I don’t want to make it seem like, oh, this is an easy thing you can do. For example, should the person doing the coding read a sentence as literally written or read it as what they think it means? And that’s a tricky one, and so you have to make a decision in how you’re training your human coders to think about these things, because the tool doesn’t understand anything about context.
The example of this that I give: I just produced the story shape for a book that my son had read, so I showed him the plot and I said, what do you think of this, does this match your sense of the journey of the book? And he says, “Well dad, it’s good until right here. This moment here your tool is showing as a positive spike in the narrative, but that’s actually the moment when the bad guys scored a victory and they’re back at their camp celebrating.” So, as a reader, he feels like that’s a negative moment, but the language in the book is all positive. So what do you do?
The good news, at least based on the analysis that I have done, is that this situation is rare, that an author would have a sustained chapter where the language says the opposite of what we are actually meant to feel. I gave you the example of the word “not” earlier, and it’s the same thing. What happens is that when a writer writes, she doesn’t put negation in one sentence after another. It happens once and the other sentences provide context that clarifies the emotions we’re meant to experience.
You mentioned all these people writing in with different applications of this package. Have you ever thought, ‘man, I wish someone would do this with this?”
No, I haven’t had a moment where I thought, ‘why hasn’t anybody done this yet?’ No, no — it’s more that I’m surprised by the different ways that people are using it.
You have a new book coming out in September called Bestseller Code: Anatomy of a blockbuster novel. Did you use Syuzhet?
We have one chapter on plot shapes that uses the newest version of the Syuzhet package. I don’t want to scoop the book, but one of the things Andy Reagan found is that there wasn’t a particular plot shape that correlated highly with a successful story. That’s what we found as well. So it’s not like all the bestsellers are “man in hole” shapes or Cinderella stories.
Right, I was thinking, “I want to test that,” and how could you do this in journalism? I thought even a series of visuals, of multiples, to see the shapes of the stories on The New York Times bestsellers list. So it’s interesting that that’s the finding.
Yeah, actually we could have done that. We could have taken just one week of the Times list and said “here are the different shapes this week.” Though we did not find any one shape that is highly correlated with bestselling, we did discover a particular feature of plot that appears in certain types of bestsellers. About 70% of that chapter is about “Fifty Shades of Grey,” so there is a little hint for you.
In terms of other people that you keep an eye on, that you follow, that you watch in the digital humanities, who would you recommend following and what tools would you recommend checking out?
You know, there are a lot of people doing really good work right now, and if you ask me to make a list on the spot, I know I’m going to forget all kinds of good folks. But certainly the text mining humanists involved in the Novel TM group would be at the top of my list. All those people are really good, so send your readers to the NovelTM web site.
There are also some fantastic people who are in computer science and natural language processing. Their work is not going to be as easily accessible to the lay reader, but I’d also recommend your readers check out the work of David Mimno who’s at Cornell, David Blei at Columbia and everyone involved in the Natural Language Processing group at Stanford — these are people I follow who work at the intersections of language and computer science. These are the people who are innovating the tools.
- Four Tips on Gamifying Journalism From Al Jazeera’s Juliana Ruhfus - October 4, 2016
- Tips and Tutorials from London’s Journocoders Meetup Group - September 1, 2016
- How one digital humanist visualized the shapes of 50,000 novels - August 10, 2016



